Feature flags are terrific, but it's inarguable that left unattended, they can clutter your codebase. Without regular maintenance, flags can easily turn into "zombie flags"—leftover code that no longer serves a purpose but clutters your codebase and slows down development. Oh no 🧟🧟🧟! Prefab is here to change that, with powerful features for managing and optimizing your flags, so you can focus on innovation instead of maintenance.
The first feature we're rolling out is a simple one: a "Has it released yet?" indicator. This helps you keep track of which flags have been deployed to your various environments. It's a quick way to see if a flag you're looking at is live in production, or still just in development.
Zombie flags are a natural byproduct of iterative development, but they can become a real pain point if left unchecked. With our built-in zombie detection, you can automatically identify and remove stale flags that are no longer in use. This not only helps keep your codebase clean but also improves overall performance, as your system no longer has to account for inactive conditions that could bog down processes.
The 🧟 detector goes off if a flag once had evaluation traffic, but we haven't seen any evaluation traffic in 14 days.
Bring it all together and your Feature Flag overview page now gives you a clear picture of your flag's lifecycle.
We're also releasing tagging today. Prefab now allows you to tag feature flags & configs. This helps our bigger teams keep a handle on what flags are what and powers our ABAC system. This organization makes it easy for teams to locate, modify, or retire flags as they scale, so your system remains both flexible and manageable as it grows.
Adding a tag is as simple as picking your tag from the dropdown and hitting save.
We believe speed is more than a feature. Speed is the most important feature.
He's not wrong. The faster your app becomes interactive, the more likely your users are to stick around. The more likely they are to stick around, the more likely they are to convert. The more likely they are to convert, the more money you make.
It isn't hard to follow the trail from Speed to Money. But keeping things speedy isn't easy as you add features.
As a web developer, you'll eventually be asked to add A/B testing or feature flags to your app. But you're wizened enough to know that every HTTP request is a performance hit. Slapping in a third-party SaaS JavaScript library to handle A/B testing or feature flags will slow down your app.
A/B testing is particularly egregious because you don't even know what content to show until you've made a request to a third-party server. The user is either watching spinners while waiting for the content to load or they see a FOOC (Flash of Original Content) where the default content is shown before the A/B test content is loaded.
FOOC is the new FOUC (Flash of Unstyled Content). It's jarring, confusing, and makes things feel broken.
Spinners are not the answer. They're a band-aid on a bullet wound.
Your users deserve better.
The best way to avoid FOOC and performance hits is to render the content server-side.
If you're rendering your content client-side (like with React or Vue), you're already taking a performance hit. You're asking the user to download a bunch of JavaScript and have it execute before they can interact with the page.
This is a calculated trade-off. You're betting that the rest of the user experience will be so good that they'll forgive the initial load time.
Hybrid apps (server-side rendered with client-side interactivity) attempt to be the best of both worlds. You get the speed of server-side rendering with the interactivity of client-side rendering.
This makes the bet a little safer. You can show the user the content immediately and then let the JavaScript take over to make the page interactive.
How do you add A/B testing, feature flags, and live config to your hybrid app without the performance hit? If you can't render the entire content server-side, then you need to evaluate the rules server-side to bootstrap the page. Many A/B testing and feature flag services can't provide this because they're built around an HTTP request. Prefab can.
Prefab's server-side SDKs let you do A/B testing, feature flags, and live config without the overhead of a blocking HTTP request (0ms).
How is this possible? Prefab SDKs load the entire ruleset for your organization into memory on your server, so lookups are instant. They’re kept up-to-date with an SSE push-based system, so you don't have to worry about stale data.
Since this data is already in memory, why not use it to evaluate all the rules server-side and skip the HTTP request? That's what Prefab does.
Starting with our Ruby SDK, you can bootstrap your page with feature flags and config values. There are two flavors to choose from.
Prefab.bootstrap_javascript(context) can be used in conjunction with our JavaScript Client or React Client. It bootstraps the page with the evaluated rules for the current context but still allows you to use the built-in goodness of those clients (like updating the values when contexts change, polling, telemetry, etc). You don't need an HTTP request unless something changes about the evaluation context.
When I took a step back to behold my beloved zero HTTP-request client-side Feature Flags, I realized I still wanted more. What's better than zero HTTP requests? Zero JavaScript dependencies.
Prefab.generate_javascript_stub(context, callback = nil) will give you feature flags and config values for your current context. You can provide an optional callback to record experiment exposures or other metrics. You'll get a global prefab object for get and isEnabled checks. There's no dependency on the JavaScript or React clients.
You can use either in your ERB (or other server-side templates) to render the content server-side. No FOOC. No spinners. Just fast, interactive content.
Give it a try today! Your users will thank you.
Here's a before and after to help visualize the difference:
Before: Client-side
After: Server-side w/ Stub
After: Server-side w/ Bootstrapping
The user has to wait for the HTTP request to complete before the final content is shown. We either show the original content or a spinner while we wait for the response. This is a performance hit and can lead to a FOOC.
The user doesn't have to wait for an HTTP request to complete. The content is shown immediately. The feature flags and config values are bootstrapped into the page and evaluated server-side.
The user doesn't have to wait for an HTTP request to complete. The content is shown immediately. The feature flags and config values are bootstrapped into the page and evaluated server-side. The developer gets the full power of the JavaScript/React clients, and the client can still update the values as needed if the context changes.
We're starting with Ruby but working to add this functionality to all of our server-side SDKs. We want to make it as easy as possible for you to get the benefits of A/B testing, feature flags, and live config without the performance hit.
Let me know if you’d like to help us test this functionality in your favorite language. I'd love to hear from you.
Well, it isn't 0ms, but the good news is that we've spent a lot of time and effort making a robust global delivery network to serve this data as fast as possible and as close to your users as possible.
How can you change logging levels for a FastAPI application without restarting? This solution uses a log filter that is dynamically configurable via the Prefab UI. This approach allows you to change logging levels for both uvicorn and FastAPI without the need to restart the server, providing greater flexibility and control over your application's logging behavior.
First, let's set up our project dependencies. We'll be using the prefab-cloud-python library to manage our dynamic logging. Add the following to your pyproject.toml file:
Now, let's configure our logger in the main.py file of our FastAPI application:
#main.py # this will read PREFAB_API_KEY from env prefab_cloud_python.set_options(prefab_cloud_python.Options()) # normal logging setup root_logger = logging.getLogger() root_logger.setLevel(logging.DEBUG)# set to DEBUG so that LoggerFilter will see all log records ch = logging.StreamHandler(sys.stdout) ch.setFormatter(logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")) root_logger.addHandler(ch) # key step - add the Prefab LoggerFilter to the StreamHandler ch.addFilter(LoggerFilter()) # get an instance of the logger logger = logging.getLogger("my-application")
In this configuration:
We set up Prefab Cloud options.
We configure the root logger to use DEBUG level, ensuring all log records are captured.
We create a StreamHandler to output logs to stdout.
We add a formatter to structure our log messages.
We add the Prefab LoggerFilter to the StreamHandler, which will enable dynamic log level control.
Finally, we create an instance of the logger for our application.
With our logger configured, we can now add logging to our FastAPI routes. Here's an example of how to use different log levels in a route:
@app.get("/") asyncdefroot(): logger.debug("debug something") logger.info("info something") logger.warning("warning something") logger.error("error something") logger.critical("critical something") return{"message":"Hello World from FastAPI"}
This route demonstrates logging at various levels: debug, info, warning, error, and critical. With our dynamic logging setup, we can control which of these messages are actually output based on the current log level configuration.
If we run this and goto localhost:8000 we see the following in the logs:
Now that we have our dynamic logging setup in place, we can change the log levels on the fly using the Prefab Cloud UI. Here's how you can do it:
Log in to your Prefab dashboard.
Navigate to the "Logging" section.
Set the value to the desired log level (e.g., "DEBUG", "INFO", "WARNING", "ERROR", or "CRITICAL").
The new log level will be applied to your application almost immediately, without requiring a restart. For example, if you set the log level to "DEBUG", all log messages with a severity of DEBUG and above will be displayed, like this:
Here's a quick look of how you might adjust the log level. In this exampel we've set the root logger to WARN and the my-application logger to DEBUG for a particular user, else WARN, and we've set the uvicorn logger to INFO.
To help you estimate how many log lines will be output at each log level, you can hover over the logger to see the log volume.
To ensure that uvicorn (the ASGI server we're using to run our FastAPI application) also uses our custom logger, we need to modify how we run the application and set log_config=None.
if __name__ =="__main__": import uvicorn uvicorn.run("__main__:app", host="0.0.0.0", port=8000,reload=True, log_config=None)
By setting log_config=None, we're telling uvicorn to use the root logger we've configured, which includes our dynamic logging setup. If you're running uvicorn from the command line you can run uvicorn --reload --log-config empty_log_config.json with the following empty_log_config.json
With this setup, you now have a FastAPI application with dynamic logging capabilities. You can change log levels on the fly using Prefab, allowing you to adjust the verbosity of your logs without restarting your application. This can be incredibly useful for debugging issues in production or temporarily increasing log detail for specific components of your system.
As part of our recent "belt and suspenders" reliability improvements, we updated our clients to route all connections through Fastly, including the Server-Sent Events (SSE) connections we use to update configurations in our clients almost instantly. Unfortunately, our experience with SSE over the streaming-miss feature wasn't great, and we had to quickly go back to clients to that direct traffic straight to our infrastructure. We wanted to share some notes about this process.
We sell Feature Flags, and a big part of that is that feature flag changes are a dish best served instantly. Server Sent Events (SSE) achieves this by keeping a connection open and pushing updates as they happen. This is great, but it requires a long-lived connection and managing all of those open connections isn't trivial.
I was particularly excited to use the request collapsing and streaming miss features as described on Fastly's blog to move thousands of long-lived connections from our API services to Fastly. These features don't incur additional costs beyond standard request and transfer pricing, so it seemed too good to pass up. Unfortunately, we learned the hard way that what works in demos and testing doesn't always translate well to the real world. In particular, I failed to heed these lines from the documentation:
For requests to be collapsed together, the origin response must be cacheable and still 'fresh' at the time of the new request. However, if the server has ended the response, and the resource is still considered fresh, it will be in the Fastly cache and new requests will simply receive a full copy of the cached data immediately instead of receiving a stream.
This sounds reasonable, but I failed to consider what it actually means in practice. I expected the combination of request collapsing and streaming miss features would always produce long-lived connections for our SSE use case. However, when our server ended the connection before the scheduled cache expiry, Fastly returned very short-lived successful (200 OK) requests instead of long lived connections.
As our largest customer updated their prefab clients, our API servers experienced a significant reduction in connections. Yay! However, we soon noticed an unexpected surge in streaming logs from Fastly. The volume was so high that we had to scale up our log processing capabilities and investigate potential bottlenecks. Upon closer inspection, I discovered that many of these logs showed requests to our SSE endpoint lasting only about 25 milliseconds.
It's worth noting that our customers' data updates remained unaffected during this period. The issue manifested as a much higher number of outbound connections than anticipated.
Initially, we suspected we might be hitting connection count limits, but our tests to verify this were inconclusive. It took a couple of days before I realized the correlation: these spikes occurred whenever we restarted our API to deploy changes.
We use 5-minute-long SSE connections with periodic keep-alives. Under normal circumstances, the prefab client would connect to Fastly and remain connected for up to five minutes. However, when our backend server restarted (unexpectedly for Fastly), our client would connect for only a few milliseconds, receive the full cached-to-date response with a 200 status code, and then repeatedly reconnect for the remainder of the cache TTL.
To probe Fastly's behavior, we used a simple SSE client implementation, shown below:
defconnect(): headers ={ "Accept":"text/event-stream", "testHeader":"python-test", "Accept-Encoding":"identity" } whileTrue: start_time = time.time() lines =0 try: with requests.get(URL, headers=headers, stream=True, timeout=(10,30))as response: response.raise_for_status() if response.ok: for line in response.iter_lines(decode_unicode=True): if line: lines +=1 end_time = time.time() LOGGER.warning(f"read {lines} lines in {end_time - start_time} seconds") except Exception as e: LOGGER.error(f"Unexpected error: {str(e)}") # a real client would do backoff in case of error
Experience quickly suggests that this code should implement a backoff strategy for errors (which our real clients do). However, until this incident, I hadn't considered that this code—designed to process connections for minutes at a time—should also backoff when faced with "successful" but very short connections.
We have clients in many languages and, consequently, many different SSE implementations—some open-source, some written in-house. Surprisingly, only one of these appears to have a setting to handle the short connection situation we encountered.
While the absence of additional costs for using streaming-miss and request collapsing is tempting, it's not an ideal solution for SSE. If you decide to use Fastly in this manner, it's crucial to understand how your clients behave when encountering rapidly closed yet successful responses. Implementing a minimum reconnection time can help mitigate request spikes, though they'll still occur—just not as severely as if you hadn't considered this behavior at all.
For now we’re back to directly hosting the long lived SSE connections on our API nodes. In the weeks ahead we’ll look at using push-based, SSE-specific tooling like Fastly’s Fanout or roll our own pushpin instances in-house.
tip
We worked with Fastly support to understand what was going on here and have been offered a credit for our misunderstanding; they’ll also be updating the older SSE blog post with new information.
Huge thanks to the team at Fastly for their help and understanding here. Software is hard and mistakes happen. Turning an expensive oops into a learning opportunity is a win for everyone and makes us more confident that Fastly will continue to be there for us as we grow.
Prefab Founding Engineer. Three-time dad. Polyglot. I am a pleaser. He/him.
I've been playing around with Expo for a few months now, and I'm impressed with how easy it is to get a React Native app up and running. It's a great way to build a cross-platform app without having to write everything twice (once for iOS and once for Android).
So, I'm excited to announce that we've released a React Native client for Prefab. This client makes it easy to use Prefab's feature flags and live config in your mobile app.
📣 We'd love to hear about the cool stuff you're doing with Prefab and React Native. Just click the little chat widget in the bottom corner of the screen and say hi. We're always happy to help out with any questions you might have.
Google Tag Manager works by allowing you to define tags in a web UI, which are then inserted into your code via a small snippet. The concept is simple enough and it helps grease the wheels between marketing and engineerings. But the problem comes when you run a Google PageSpeed Insights test.
Almost immediately, you get feedback that your website’s performance has taken a hit. So here’s the frustrating part: on one hand, Google tells you to install Tag Manager to use Google Analytics and Ads. On the other hand, it tells you to uninstall it to speed up your site! It’s a catch-22. You want the flexibility of adding tags on the fly, but at what cost?
The issue is that once you add Google Tag Manager to your site, every page has to make a request to determine which tags to load. The page loads, requests the tags, and only then can it pull in additional scripts as needed.
That's:
DNS lookup
TCP connection
Waiting for the response
Content Download
JS Parse
JS Execute
before you even know what JavaScripts you want to start loading.
Let's use just a single tag to keep things simple.
The easiest way to add a tag is to just paste it into the head of your page. We'll use Posthog as our example tag and add it to a dirt simple Rails "hello world" page.
Result:
Page load event in 105ms.
Posthog ready around 150ms.
Marketing has no visibility and doesn't love it because they have to make a ticket to add a tag.
Google Tag Manager: 285ms (90% slower than the original)
To switch over to Google Tag Manager, your code will change to this.
<head> ... <!-- Google Tag Manager --> <script>(function(w,d,s,l,i){w[l]=w[l]||[];w[l].push({'gtm.start': newDate().getTime(),event:'gtm.js'});var f=d.getElementsByTagName(s)[0], j=d.createElement(s),dl=l!='dataLayer'?'&l='+l:'';j.async=true;j.src= 'https://www.googletagmanager.com/gtm.js?id='+i+dl;f.parentNode.insertBefore(j,f); })(window,document,'script','dataLayer','GTM-ABCDEFG');</script> <!-- End Google Tag Manager --> </head>
And of course you can see the problem already, the code no longer knows about the Posthog script. It won't know until the GTM script loads & runs.
Result:
Page load event in 210ms.
Posthog ready around 285ms. 90% slower than the original.
Yikes! A 100ms+ delay just from adding Google Tag Manager. According to GPT anyway in 2024, Google Tag Manager (GTM) is used by approximately 48.9% of all websites. That’s a lot of time spent waiting.
The ideal solution would be for your pages to somehow "know" which tags to load without that extra round trip. But for that to happen, your server-side frameworks would need to coordinate and decide on the correct tags for each page... hey wait a minute...
Solution: Dynamic Configuration: 110ms (As fast as the original)
And that’s exactly where dynamic configuration comes to the rescue.
Dynamic configuration allows your pages to pre-render with the correct tags, without making additional requests post-load. This eliminates the performance hit that comes from waiting for tags to load.
Are we giving anything up by not using Google Tag Manager? Audit trail, targeting, testing, etc?
No! In fact, I'd argue that you're going to be happier with dynamic configuration. Why?
Oversight: With a Slack integration, you can track who’s making changes to your script tags, preventing the scenario where marketing adds extra tracking pixels without you knowing.
Audit Logging: You still get the audit logs that Google Tag Manager offers, but now they’re integrated with the rest of your dynamic configuration.
Access Control: You can control who has access to make changes to your dynamic configurations with fine grained ABAC.
Unified targeting: You retain all the capabilites of Google Tag Manager's targeting. Want some scripts to load only on internal pages? No problem. Want to only load the conversion tracking script on your checkout page? No problem. #its-just-config so you have good choices about whether to make these separate configs or one big one.
One example of how we could do this would be like so:
In short, dynamic configuration not only solves the performance problem but also improves transparency and oversight.
If you're interested in saving 100ms on page speed while retaining the flexibility of Google Tag Manager consider using a dynamic configuration tool like Prefab.
Note: If your applications is not server side rendered, you can still use dynamic configuration as a replacement for Google Tag Manager, but the performance win will be much smaller. Prefab client libraries will make a request and pull back both you feature flags and your configuration and then you can use the same eval to load the scripts. The win here vs GTM would be that you're using a single tool, not a feature flag tool and and tag manager, but we will still need to make a request to get the scripts. You may still appreciate the Slack integration and audit logs of Prefab as a way to manage your tags.
Prefab Founding Engineer. Three-time dad. Polyglot. I am a pleaser. He/him.
At Prefab, we care about speed and reliability. We’re asking our customers to trust us in their critical code paths, so we need to be near bulletproof.
Part of obsessing about reliability is looking at the system as a whole and asking, “What happens if this part fails? How do we make sure our customers and their users are unaffected?”
And, sure, there's a bit a self-interest here: I don't want to be woken up at 3 AM because something is down. We also don't want our customers to be woken up at 3 AM because something is down.
We took a look our architecture, asked a lot of questions, and realized we could do better.
The previous architecture for serving Frontend clients looked like this:
This works well. The CDN (Fastly) can cache contexts that it has seen before and serve them speedily around the globe. Unseen contexts (or requests after flag rules have changed) hit the API (which calculates the results in a few ms) and are newly cached in the CDN.
Fastly is reliable, but if it isn't responding or is slow, the library falls back to the API directly.
Looking at this diagram, it isn't terrible. The failover to hit the API directly gives us some redundancy.
But there are two points of failure:
Google Spanner: This is highly available, but it could go down. If it goes down, the API can't serve requests because it can't get the latest rulesets
The API server
If either of these isn't working, the CDN can serve stale content until things are working again. If there is no cached content for the user, the client-side library will return false for flags and undefined for configs. This is behavior the developer can code against, but it's not ideal.
Looking back on human history (or just watching an old episode of America’s Funniest Home Videos), it seems few things are funnier than someone else’s pants falling down (sorry, I don't make the rules). On the flip side, few things are more embarrassing than one’s own pants falling down. To that end, humanity created the belt and suspenders combo. If the belt malfunctions, no worries; the suspenders will hold your pants high.
Looking at this diagram, it was clear that we needed a belt and suspenders. We’ll arbitrarily call the old approach (CDN + API + Spanner) the suspenders. How do we build out the belt?
First, what does the API do, exactly? It is a simple HTTP server that recieves requests that bear Context (about the current user) and an API key. It validates the API key, reads the rulesets from Spanner, evaluates the rulesets against the context, and returns the results.
To insulate us from Spanner being down, we'd need a copy of the rulesets somewhere else. We use protobufs to serialize the rulesets internally so the easiest way to get a copy of the rulesets is to write them to a file in cloud storage. We can write to as many cloud storage hosts as we want (for redundancy), and they can be read from anywhere in the world. James built out a data pipeline to write any changes to the rulesets to cloud storage.
To protect against the API server being down, we needed to build out a Global Delivery Network service to read those files and evaluate them against the context. We knew that we wanted to run this service as close to the user as possible to keep latency minimal. Being globally distributed also gives us some redundancy if any one region is having issues.
I started work on this when we were wrapping up our Go SDK. We found Go fast, developer-friendly, and fun to work with. It made sense to use Go for the service.
I'd been following Fly.io for a while, used them in a hobby project, and was impressed with their region support. They seemed like a natural fit.
We threw a CDN in front of the service to cache responses. CDN + Global Delivery Service = Belt.
Finally, we had to update the front-end clients to try the belt before suspenders. If the CDN has fresh content, we serve it from a globally nearby location. If the CDN misses, then we hit an edge server running on Fly.io’s globally-available hosts and cache the response for next time.
Our reliability story is now improved greatly 🎉 If we can’t get a good response from the belt, then we fail over to suspenders. If we can't get a good result from suspenders, we hit the Global Delivery Network (servers on Fly) directly.
Here's the best case scenario: Your context has been cached in the belt CDN and is globally distributed. The CDN serves the content from a nearby location, and the user gets a fast response.
If the content isn't cached in the belt CDN, we hit the Global Delivery Network. The Global Delivery Network is a set of edge servers running on Fly.io. The belt CDN will cache the response for next time.
After trying the belt and finding the CDN or Global Delivery Network aren't immediately responsive, we fall back to the suspenders. The suspenders CDN will serve the content from a nearby location, and the user gets a fast response. Because the edge server is geographically closer the CDN, the response will be faster.
After trying the belt and finding the CDN or Global Delivery Network aren't immediately responsive, we fall back to the suspenders. If the content isn't cached in the suspenders CDN, we hit the API. The suspenders CDN will cache the response for next time.
After trying the belt and finding the CDN and Global Delivery Network aren't immediately responsive, we fall back to the suspenders.
After trying the suspenders and finding the CDN or API or Spanner is down, we fall back to the hitting the Global Delivery Network server directly. Since the edge server is geographically close to the user, the response will be faster than hitting the API directly.
Belt and suspenders. If the belt fails, the suspenders will serve. If the belt and suspenders fail, the Global Delivery Network will serve.
We're using this belt+suspenders approach for our server-side SDKs as well, so they also benefit from geographically proximate servers and redundancy.
Let's compare the architecture from before and after:
Before
After
Speed Improvements (more than just a nice side effect)
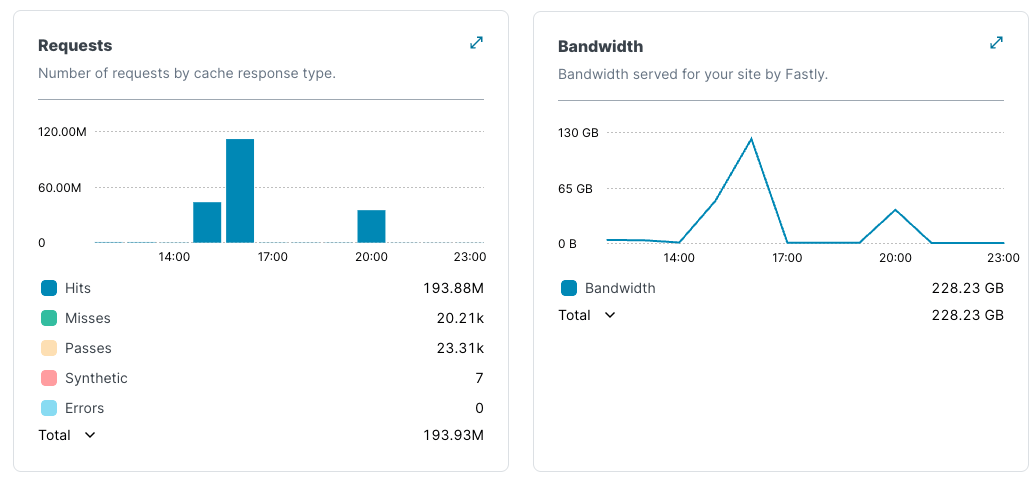
The API server in the original diagram was plenty fast — it took a few milliseconds to serve the request. But the API server is not globaly distributed and at some point, latency becomes more about where you are (geographically) in relation to the server than the speed of the server itself. I'm 13 ms round-trip from us-east-1-atl-1a but 39 from us-east-1-bos-1a. In the front-end, every millisecond counts. The further you get from a server, the worse the impact.
Let's look at a particularly bad example of this. Talking to our classic endpoint from Sydney is particularly slow. Here's a WebPageTest (Native Connection, no traffic shaping) comparison of the classic endpoint and new endpoint being accessed from Sydney (with a local Sydney Fly.io server):
There's probably more room to get that blue line down a little lower further, but we haven’t gone down the path of squeezing further performance out of the belt yet (e.g., we're currently running on shared-cpu-1x:1024MB machines). But deploying at the edge already gives us savings of ~200ms in the worst-case performance for the old endpoint. We'll be observing real-world numbers to get a better feel for how we should scale the machines and shape regional strategy.
Update to the latest clients for speed improvements, and stay tuned for better performance ahead.
Feature flags are great, but paying $20-100+ / seat takes all the fun out of them. Prefab is a developer-focused Feature Flag and dynamic configuration system that lets you save 70-80% on your bill while getting a more versatile system to boot.
Because we don't charge on seats, customers have been inclined to let everyone have a seat. Whether it's marketing being able to dynamically configure a notice or junior developers who no longer need to ask in Slack for someone to change a flag, this is a boost to speed all around.
With all those seats, we needed to ensure that customers had the control they needed about who could do what. So, Q2 was all about giving our customers the visibility and control they needed to confidently switch to Prefab, get a seat for everyone, save a bunch of money, and make their systems more dynamic.
The core of our work was advanced permission work. The first part of that was building a flexible way for Prefab customers tag their flags and configuration.
Now that we have these groupings, we can use these tags and the customer's SAML roles to build customized rule sets to configure permissions within the system.
Building permissions doesn't exactly sound like fun, but we were excited to do it because it meant that our customers can now roll out Prefab more broadly to their teams, and we love the creative use cases we're seeing.
Along with access control, visibility is a huge boon to understanding the state of your dynamic system. Our top customer request: a Slack integration, is now available. This feature provides passive visibility into feature toggles within Slack, enabling easy updates and interactions with comments and emojis.
We’ve improved our support for feature flag rollouts so that you can release changes to as little as 0.1% of users, meeting our customers’ needs for precise control.
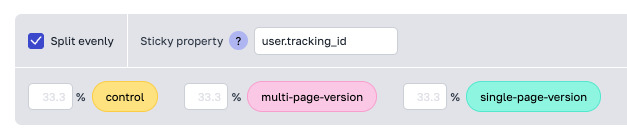
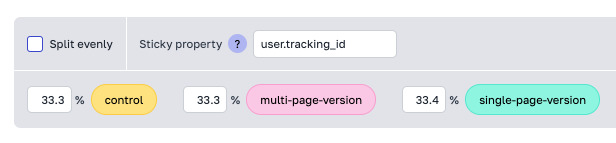
Prefab now supports even distribution for multi-arm experiments. Simply click "split evenly" for a perfectly balanced rollout of 1/3. No more 33%,33%,34% experiments here!
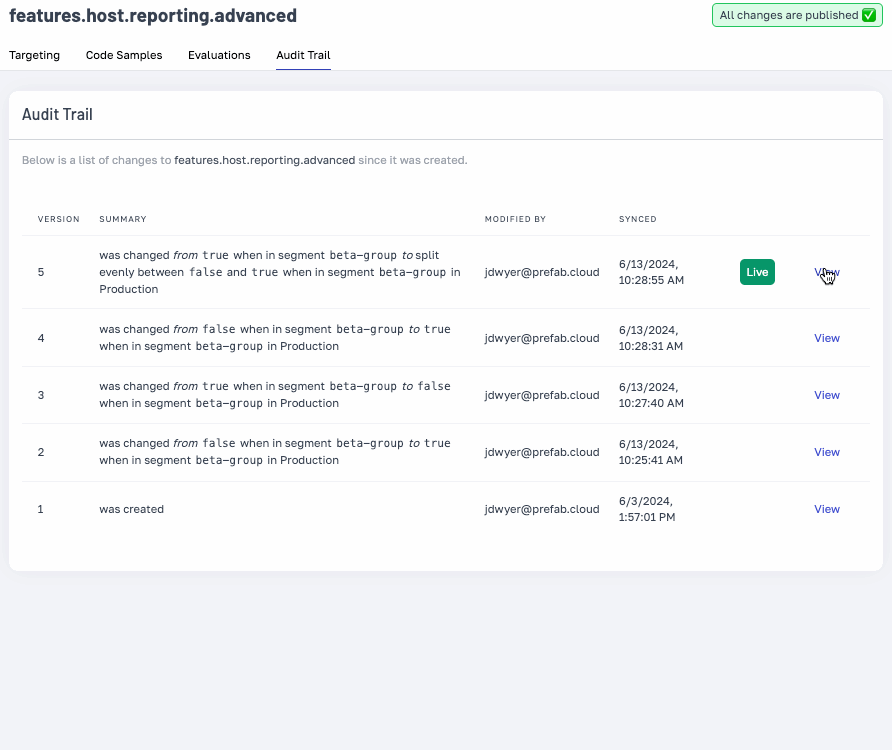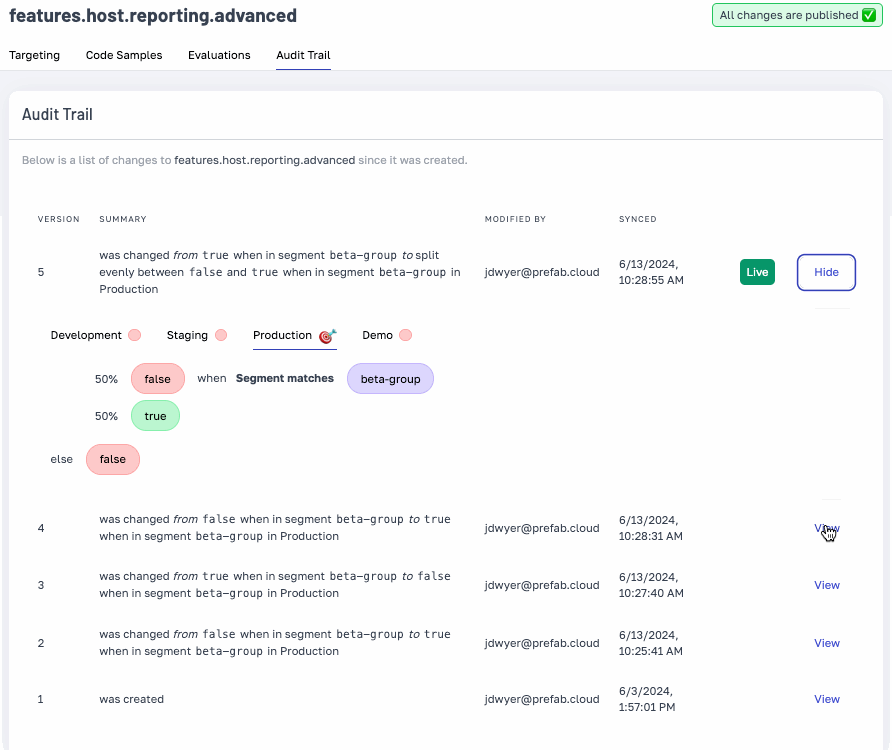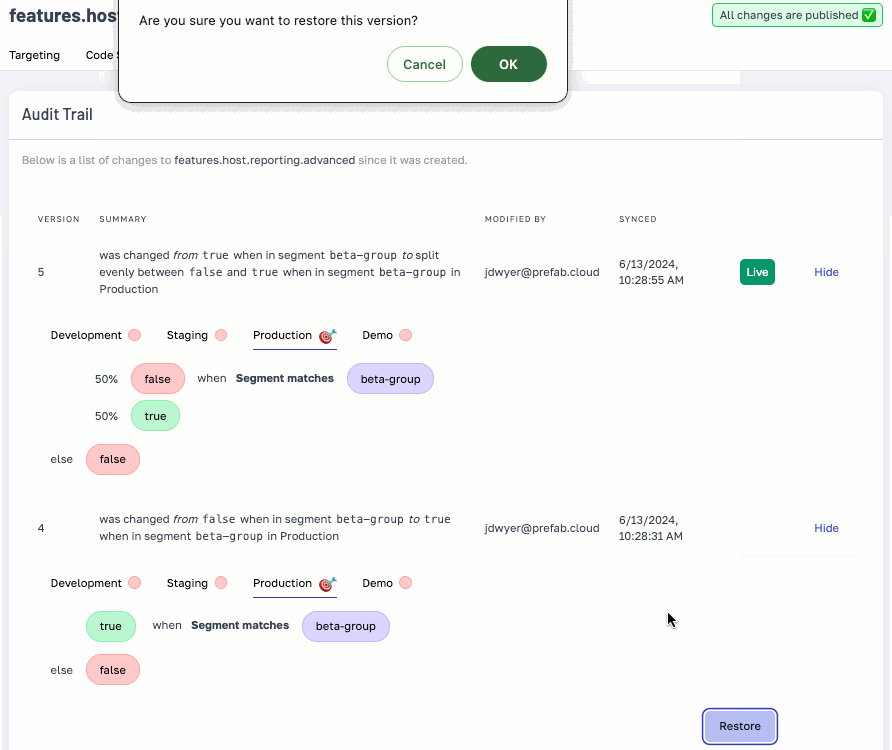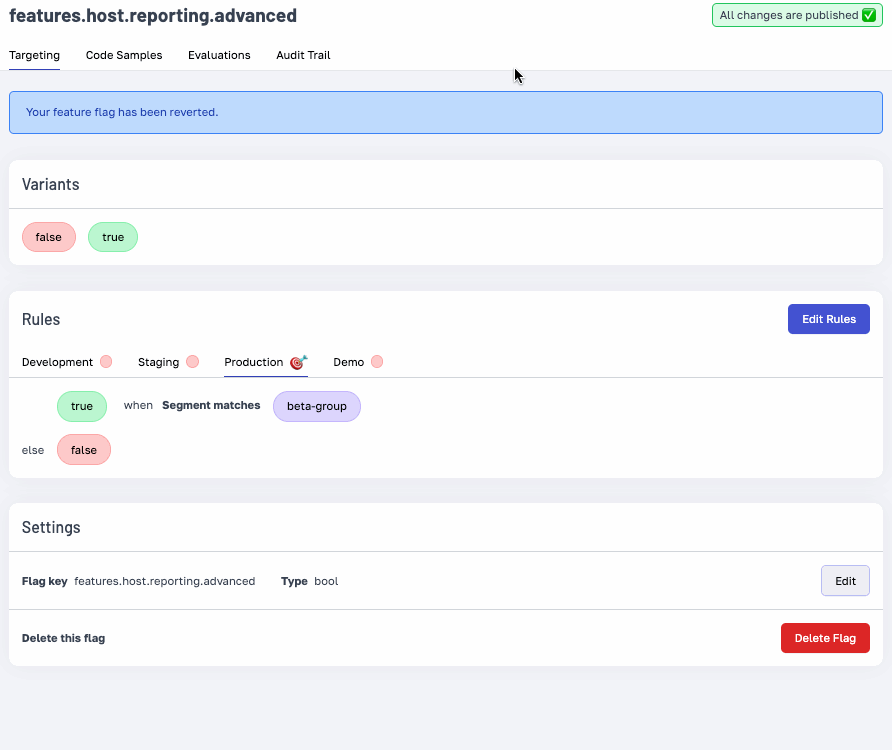
We've enhanced our audit trails with detailed change descriptions and the ability to view flag or config states at any time, ensuring comprehensive system oversight.
Easily revert to a previous configuration state with the audit trail’s new ‘Restore’ feature.
Q2 was awesome, and we are hard at work on a whole host of improvements for Q3. First and foremost, we're working to bring our evaluations to the edge, so Front-end clients get the fastest and most reliable flag evaluations possible.
Please get in touch if your Feature Flag tool isn't bringing your delight and I can share some in-progress case-studies of customers switching to Prefab.
Feature Flags and Dynamic Configuration are the control panel at the heart of your systems. This quarter, Prefab has been focussed on giving you the visibility and control you need to confidently operate your system.
This was hands down the #1 customer request we had and we were so happy to build it. Having passive visibility into what features are being turned on/off is fabulous and Slack is the perfect place for it.
It's awesome to be able to easily stay abreast of what's happening, and celebrate or ask questions in comments / emojis. 🎉🎉🎉🎉
Dynamic configuration systems like Prefab give you the ability to roll out changes very carefully. What could be more careful than only rolling out a change to 1% of users / deployments? Well, Prefab customers like a small blast radius and asked for the ability to rollout to .1% and we're excited to get that in your hands, along with a much better user experience.
You can never be too careful when switching over to the new Redis cluster.
But that's not all. Have you ever had a 3-way experiment and felt a deep underlying dissatisfaction with having to roll it out 33% 33% 34%? Same!
Well, suffer no longer, because Prefab is happy to support your rational number brain. Just click "split evenly" and you'll the equivalent of a perfect 1/3, 1/3, 1/3 split (at least as far as floating point numbers can take us).
With the great power of Prefab, comes great responsibility and now... a much improved audit trail.
With friendly descriptions of the change, and the ability to see the state of your flags or config at any point in time, you can feel confident that you know exactly what's happening in your systems.
Prefab gives your team great power to manage and control your systems across all of your deployments. From our evaluation charts, to the VS Code plugin we are committed to giving you the tools you need to understand and modify your systems safely in production. Stay tuned or follow-us for more updates.
Prefab is democratizing the core internal services that make product engineering teams go fast at big orgs that can afford 20 engineers on developer experience. Today we help organizations:
Improve MTTR by changing log levels instantly
Reduce Datadog bills by only logging / tracing when you need it or targeted to a particular user or transaction.
Save 90% vs LaunchDarkly for a robust feature flag solution
Improve local developer experience with shared secrets
Manage microservice configuration at scale with dynamic configuration.
This quarter we shipped a ton of great stuff, much of it coming straight from customer requests.
Sometimes it's the little things that make the difference. We made a ton of small tweak based on your feedback this quarter and the product is feeling tighter than ever.
Some users reported that while it was great that they could see all of the flag values for a given user, what they really wanted to be able to do was change those values. They we're pleasantly surprised when we told them they could already do that! They just needed to click the pill that didn't look clickable. Talk about hiding our light under a bushel. As much as we like secret off-menu features, we decided to go ahead and make this look clickable.
Huge improvement for those of you with tons of loggers. Have 500+ loggers? (I'm looking at you Java). Find the one you want to turn on instantly with a quick little search.
Our Python client got a huge overhaul this quarter and is ready to roll. Check out the full docs. The code is tighter, the telemetry is in and the integration with standard Python logging frameworks is much improved.
Ruby Client Logging Overhaul to use SemanticLogger
In a similar vein, we did a big overhaul of the ruby client as well and we now work out of the box with the best ruby logging library out there. We were able to reduce the surface area of the library and really focus in on what we can bring to your ruby logging: being a smart filter that decides what logs to output.
If you wanted to use Prefab, but really needed to use Okta or another SAML provider, we're so excited to have removed this blocker for you.
SAML is live and we're welcoming new signups with open arms. What's particularly exciting about this to me is that we're running it ourselves. We're doing it internally, because it seems to us that everyone should be able to support SAML and this is kinda our thing: write the code one last time so that it all plays well together and we can all use it.
Ever written http.connect(timeout: Prefab.get("my.timeout')) and been worried that someone might use millisecond or seconds or minutes? Naming all your time duration configs kafka.retry.timeout-in-seconds to try to be really explicit? Well, good news because Durations are coming to Prefab.
Durations is a new type of config that acts like the java.time.Duration object or ActiveSupport::Duration in Ruby. You can specify it in whatever units you like and then retrieve it in whatever units you like. Under the covers it's stored as an ISO 8601 duration.
And in your code you can just ask the duration in whatever unit you need. Unit mismatch crises averted.
duration = Prefab.get("mysql.timeout")# P80S # a Prefab duration object that quacks like ActiveSupport::Duration mysql.connect(timeout: duration.in_milliseconds)//80000 mysql.connect(timeout: duration.in_seconds)//80 mysql.connect(timeout: duration.in_minutes)//1.5 mysql.connect(timeout: duration.in_days)//0.00001
We heard you loud and clear. Our pricing was... confusing. We've re-packaged it and we think it's a lot clearer now.
Getting into pricing made us really wonder how we stacked up to other tools in the space. It turns out the answer is... complicated. We started building the spreadsheet to help us figure out how we really compared and then decided it should really be code and then decided we might as well just share it with everyone.
Why should backend libraries like Python, Java and Ruby have all the fun? What if you want to make dynamic configuration updates to content on your website. We agreed, so we added an opt-in flag to configuration that will send config to front end libraries.
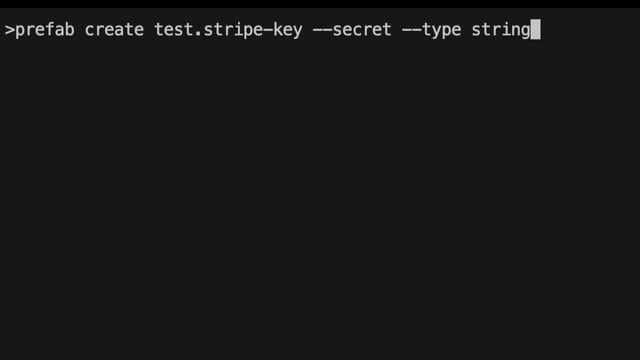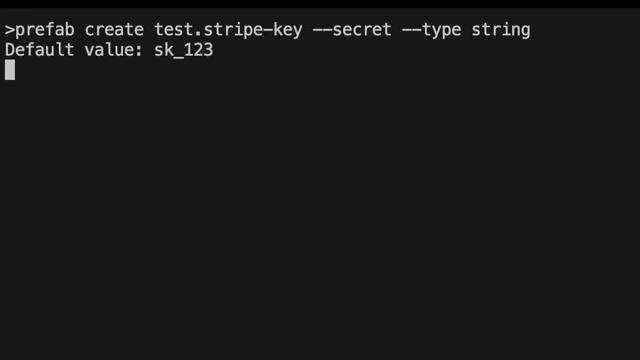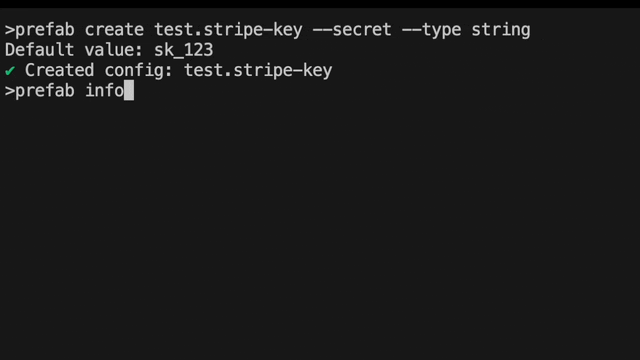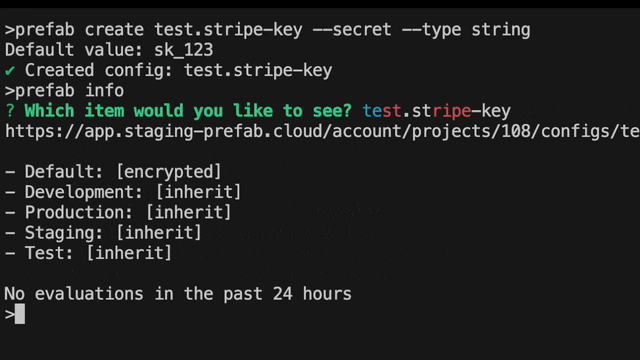
What's that command line argument again? I could never remember the exact CLI command and now that we support setting secrets via the CLI, I was getting annoyed. The solution! Something we affectionately called "drunk ceo" mode. Wouldn't it be great if all CLIs also had a mode where you could just type in what you wanted it to do and it would find the right combination of flags for you and prompt for missing information? We thought so too and Jeffrey made it happen.
Last but not least, we made some nice improvements to the libraries and the documentation around Feature Flags for our Jamstack customers. Whether you're on Clouflare, Vercel or Netlify, you should be able to get started quickly with Prefab for Feature Flags, Dynamic Logging or Configuration.
Q1 was awesome, and we are hard at work on a whole host of improvements for Q2. Our focus will be squarely on our existing customers, giving you all the tools you need to feel confident and assured that Prefab respects the core role that you're entrusted us with in your stack.
Your billing system knows user.plan == pro, but your React code needs to know if it should let the user see the "advanced reporting" tab or calculate how many "active lists" they're allowed. How do we bridge this gap? How do we go from the SKU/plan to the actual product features that should be on or off. How can we handle product entitlements with feature flags?
The naive version of these systems is pretty easy to build. We could of course put if user.plan == :pro checks everywhere, however we are going to feel pain from this almost immediately, because there are common entitlement curve-balls that will lead to spaghetti code and hard to understand systems once they are faced with reality. For today, let's see how to build a more resilient system by:
Taking a real pricing page and modeling it.
Throwing some common curve-balls at it.
Some organizations are going to want a whole separate entitlements system, but let's look at how to do this with the feature flag system you already know and love. We'll implement using Prefab, but these concepts apply to any feature flag tool.
Let's implement a portion of HubSpot SalesHub pricing page as our guinea pig here. It has a mix of on/off features as well as limits.
The first thing we need to do is model how we think about a customer's plan. Our feature flag tool is not the system of record for what SKU / billing plan a user or team is on, so we should pass that in as context to the tool. But what should that context look like?
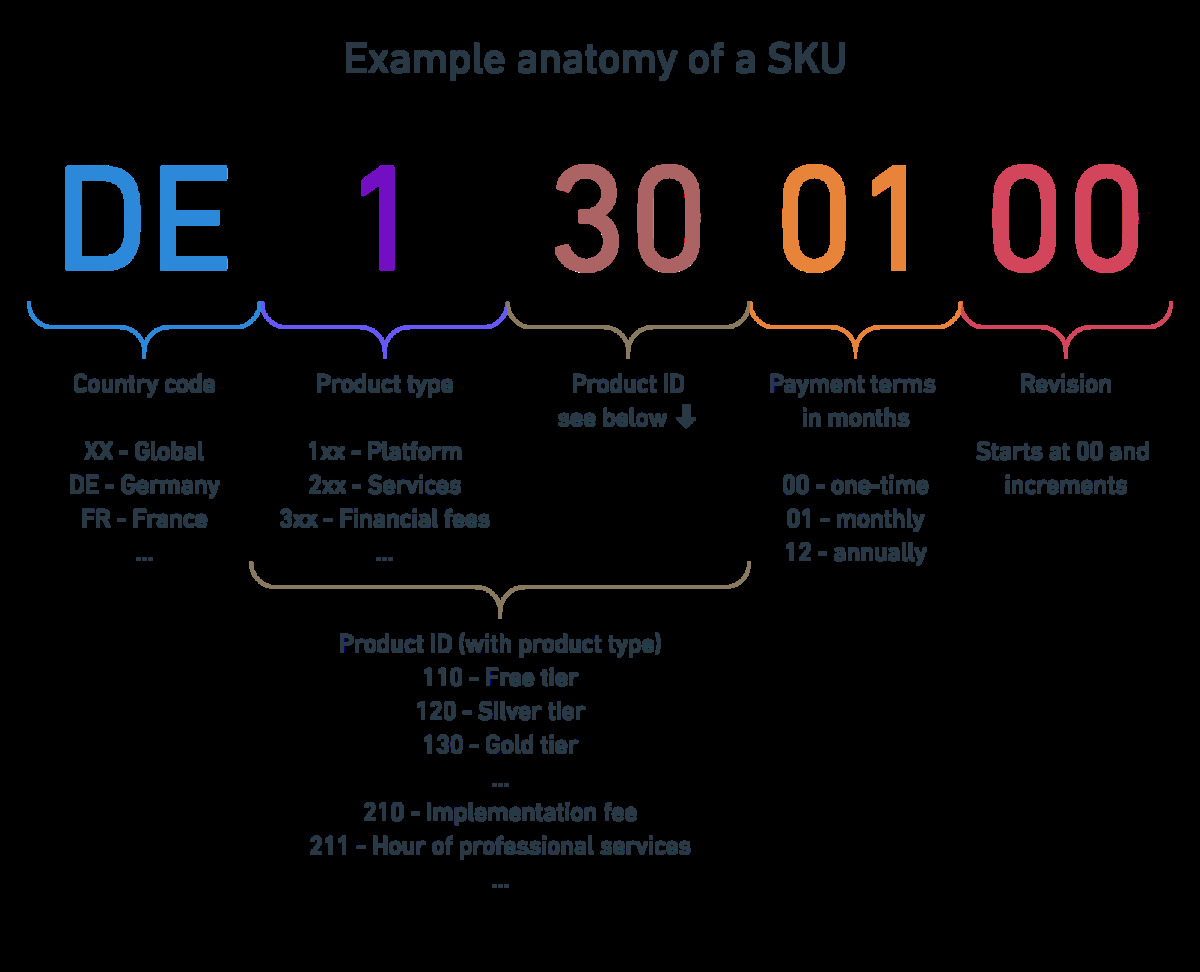
Design your pricing and tools so you can adapt them later is a great read that gives us a good place to start. I'm going to use the SKU definition from that as a start point for us, but it's worth a read in its entirety as well.
While it is helpful to have a single canonical SKU as in the image above, it will be easier to work with if we also split it up into the component parts. (I didn't use an integer for the product part because that's a bit more confusing for our example today with a product that isn't yours, but it's a fine idea).
Here's a good straw-person context we can start with:
For this curve-ball lets figure out what to do when, inevitably, sales gets in touch and says that they need to be able to demo this feature to users in their account. The user is still going to be in the starter plan, but we want to temporarily give them the same access (for this feature) as if they were in pro
The easiest way to do this is to make an one-off override for the customer that sales wants to demo to.
To do this, we can use the context search screen which lets us type in the name of the customer. From the resulting page we can see how every flag evaluates for them. We can then click and change to set the flag variant manually for them.
That creates a new rule for us, specifying that this particular user should have access to the feature. Rules are evaluated in order, so the top rule will win here.
What we did there works fine, but let's throw another curve-ball. It's pretty common to have a situation where a salesperson always wants to demo 10+ different features. We sure don't want them to have to edit 10 different flags and then remember to undo 10 different flags in order to make this happen.
A good way to make this better would be to create a segment called currently-demoing, then we can reference this segment in the rules.
When a sales person needs to demo, they can quickly add the team or user key and instantly that team will be upgraded for all flags that use this segment.
We can use this segment as a top-priority rule in the features we want to demo.
When using segments, it can be a bit more challenging to know exactly why a user is getting a feature. To help you with that, you
can use the context view again, but this time hover over the ? next to each flag. This will show you all of the rules for that flag and highlight which rule is matching. Here we can see that we are matching true because of this currently-demoing segment.
Segments are powerful and can help you bring order to your models. They will be a good aid in solving challenges around one-off contracts as well. Remember, just because you offer 3 tiers on the website, doesn't mean there isn't going to be a 4th, 5th and 6th tier once sales starts negotiating. Good naming is key to making this work so game out a number of scenarios before you commit to ensure that you have the best chance of success.
The next entitlement we'll model will be the number of "Calling Minutes". Enterprise should have 12,000, Pro 3000 and Starter 50.0
We can use a FeatureFlag with integer values here.
Let's throw in a new curve-balls this time. These limits seem like something we'll want to experiment with. Let's say we want to try reducing the number of minutes on the pro plan, but we don't want to change anything for existing users. This is where our good SKU modeling is going to help.
We can no longer just use 'plan.tier' to determine the number of calling minutes, so let's use the plan.version attribute to lock down the behavior for the Pro plan version 0.
We have our legacy pricing locked in and won't be changing existing customers. If we wanted, we could even start experimenting. To model a 50/50 split of calling minutes, we can do a percentage rollout. Note that we should be careful to select the sticky property. If we want all members on a team to have a consistent experience, we should choose team.key instead of user.key.
Dealing with product entitlements and feature flags is part science, part art, and a whole lot of not shooting yourself in the foot. It’s about laying down a flexible foundation, so you’re not boxed in when you need to evolve. And remember, it’s always smarter to hash out your game plan with someone else before you commit. Two heads are better than one, especially when one is yours :)
Make sure to consider the curve-balls we considered here:
How will you do demos?
How will you support one-off contracts?
How will keep legacy plans consistent while you iterate on new pricing?
If you’re neck-deep in figuring out how to model your features and entitlements, don’t go it alone. Ping me, and let’s nerd out over it. Because at the end of the day, we’re all just trying to make software that doesn’t suck.
I like CLIs, but I also find them frustrating. What are the options? Which options go together? I always reach for a CLI when I want something to happen RIGHT NOW, but then it's a process of reading the help page and trying to piece together an argument string.
I get it working and then promptly forget before the next time I need it.
With this in mind, we've retooled the CLI to meet you where you are. Know just what you need? Use the arguments. Can't be bothered? Just type prefab, and we'll work through things together.
Here's what it looks like to change a feature flag now.
We've pulled together the common operations that you might want to do so you can just search through them with autocomplete. Is it "set" or "update"? Type either, and you'll still find it.