Let's compare 7 top FeatureFlag providers to see how they compare.
Feature Flags are great, but there are so many tools to choose. In this comparison, we will evaluate 7 tools against the same test case. We'll test: Flipper, Prefab, Unleash, Flagsmith, LaunchDarkly, ConfigCat & Devcycle. We'll try to perform the same test case in each tool and we'll share our results & screenshots. This should be a good way to quickly compare the UIs and features.
The Test Case
In order to put these tools through their paces, we'll use a straightforward test case. Here's our scenario:
As a developer on the checkout team I would like to test 2 new checkout flows:
- A new
multi-page-version.
- A new
single-page-version.
- A
control of the existing checkout experience.
We have 4 targeting requirements:
- We don't test on our enterprise customers, so I want
team.tier = enterprise to get the control.
- I want the existing
beta-users and internal-users to try the multi-page-version. Beta users is a list of user ids. Ideally I can store this list in one place and reuse it. Internal users is anyone matching an email address ending in example.com.
- Two teams
foo.com and bar.com complained about complexity so they should evaluate the single-page-version.
- Everyone else should get a 33/33/33 split of the 3 versions.
Okay, let's see how our contestants do!
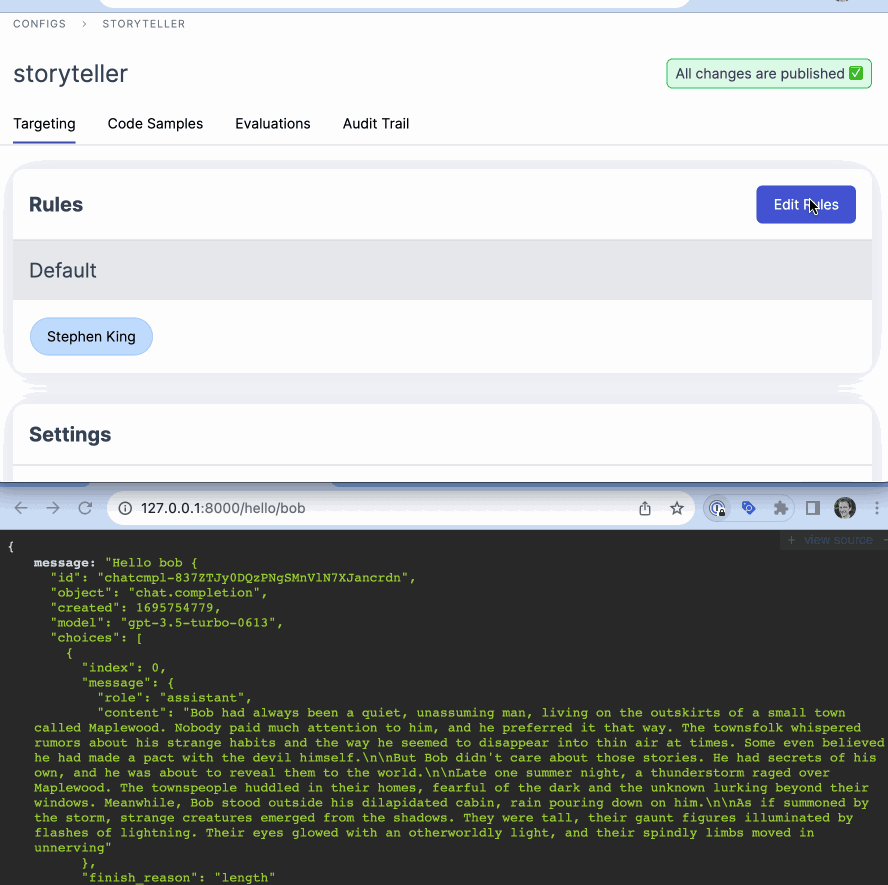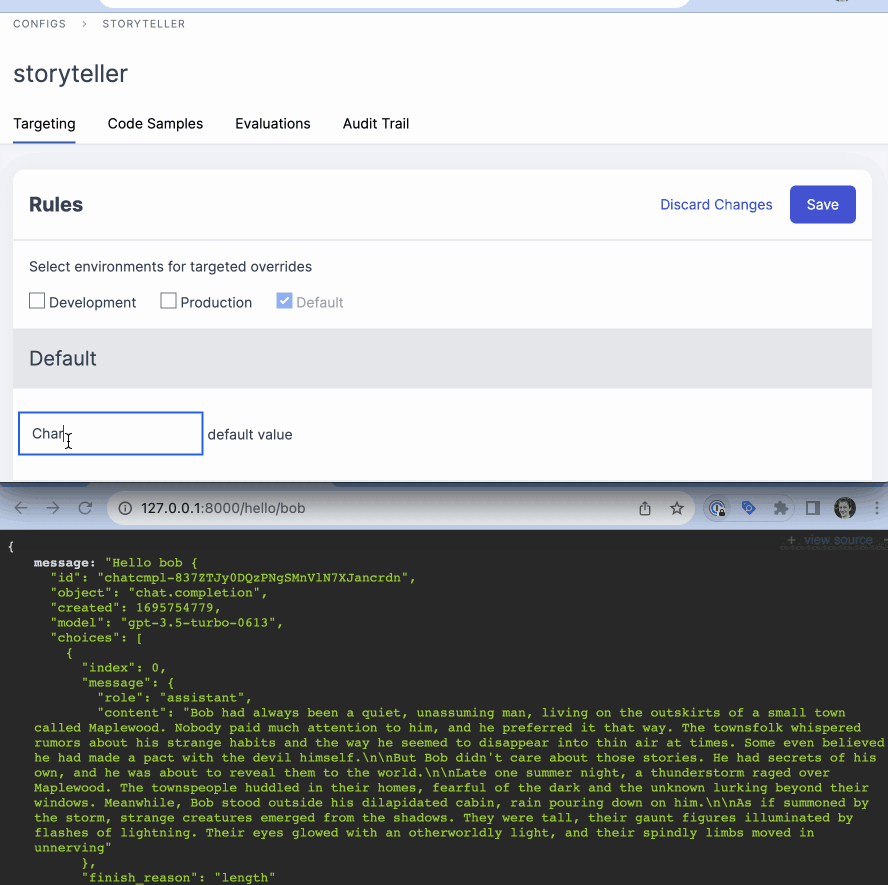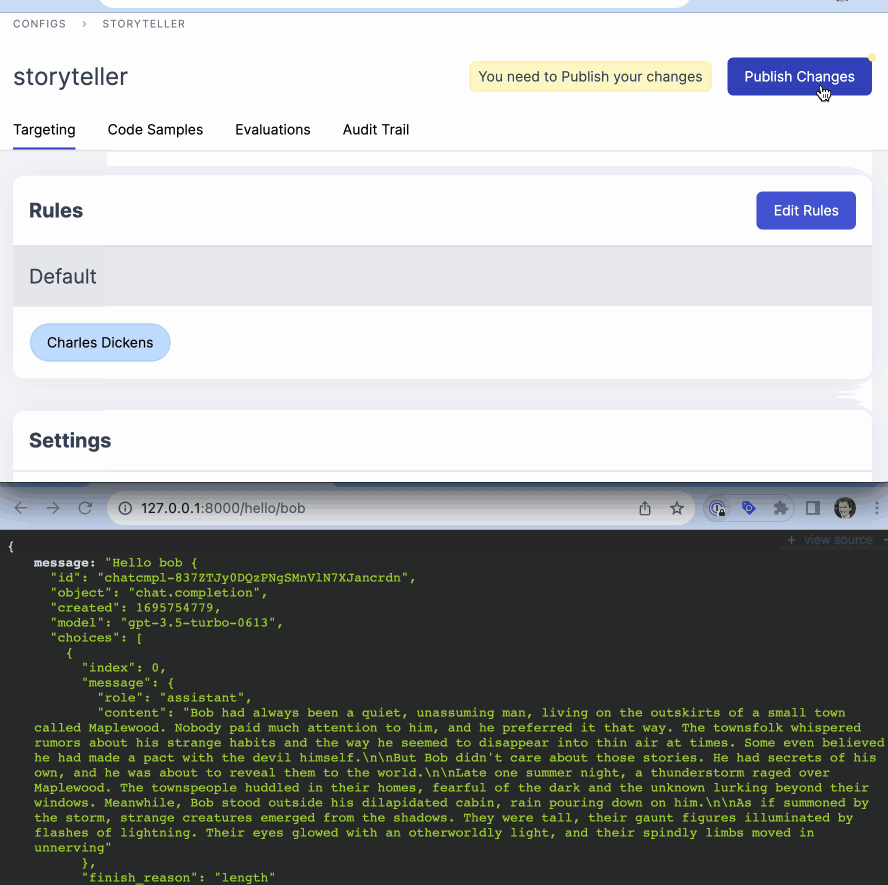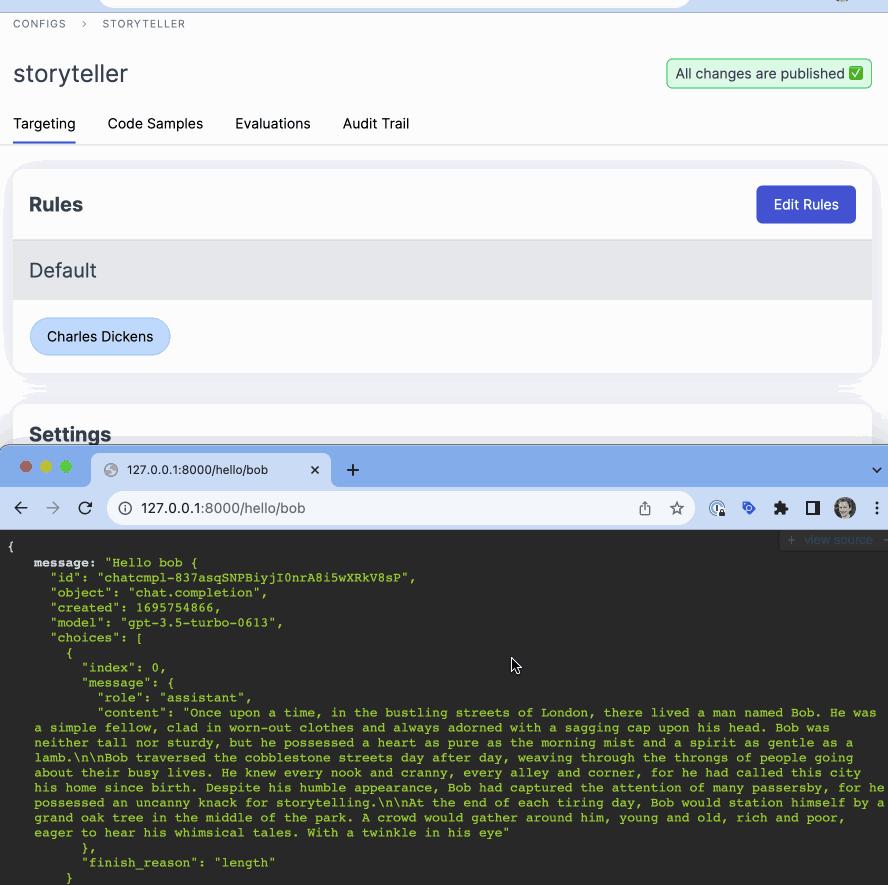
FlipperCloud
FlipperCloud is a feature flagging system born out of a popular open source ruby gem. It's particularly popular among Ruby on Rails developers due to its ergonomic design and tight integration with the Rails ecosystem. Flipper has both an open-source library and a cloud-based service.
Trying to setup our test case in Flipper.Cloud was a bit of a challenge. Flipper does not support multi-variate flags, each flag can only be a boolean. To fully nail our test case I would need to hack around this and setup 3 flags, one for each variant. Let's lower the bar a bit and change the test case to just have 2 variants on and off.
Our next requirement was to avoid the enterprise tier. Flipper.Cloud does not support specifying off for an actor or group. So we'll probably need to do this in code:
if team.tier != :enterprise && flipper.enabled?(:experiment)
end
For our beta customers and target customers, we are able to target groups. Flipper is interesting in that again the group definition happens in code. This is pretty different from the other tools we are looking at, but could be convenient for a Rails monolith with complex targeting logic.
Flipper.register(:beta_customers) do |actor|
actor.is_in_beta_group?
end
Flipper.register(:target_customers) do |actor|
actor.email.ends_with?("@foo.com")|| actor.email.ends_with?("@example.com")
end
The resulting UI looks like:
FlipperCloud Takeaways
- Best for: Teams committed to being a Rails monolith and who don't need flags in JS.
- Price: $20 / Seat
- Test Case: 🙁 No support for multi-variate flags.
- Features: Audit logs.
- Architecture: Uses server-side evaluation, with adapters. Updates are polling.
- Notes:
- No support for non boolean flags
- Can only use targeting to force into flag, not to exclude.
- Uses unusual "actors" and "groups" terminology.
- Group definitions are in code, not in UI.
Unleash
Unleash is an open-source feature flagging system with a strong focus on privacy. Let's see how it does with our test case.
Unleash has a pretty different approach to setting up our beta group and enterprise segments.
My initial approach was to add these in as "strategies" like this.
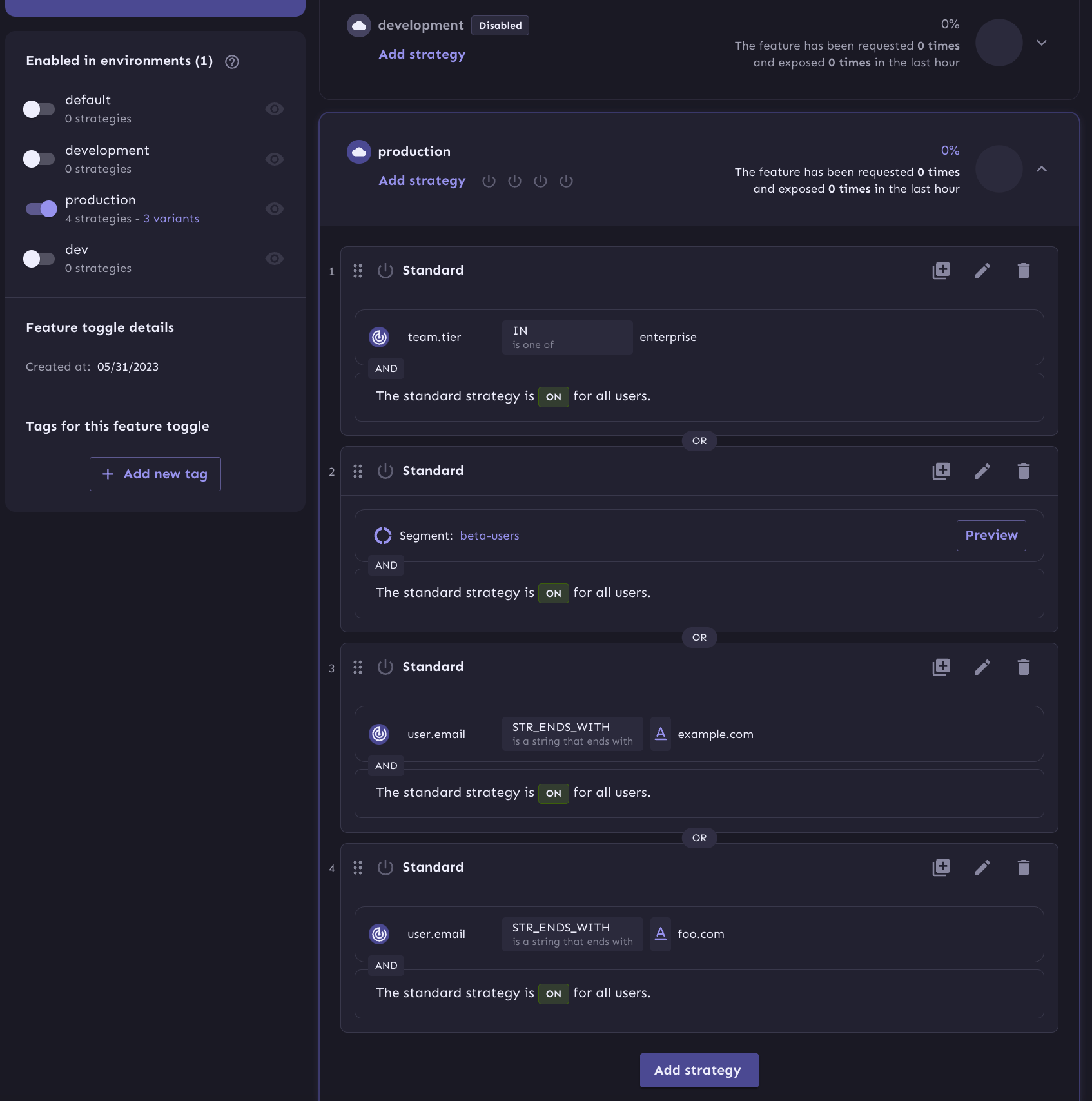
I was able to setup segments and the matching rules as you would expect,
however this doesn't work! Strategies don't include a value. These fine grained rules
only determine whether we should return the whole variant set or not.
Instead, we are meant to set overrides on the variants themselves.
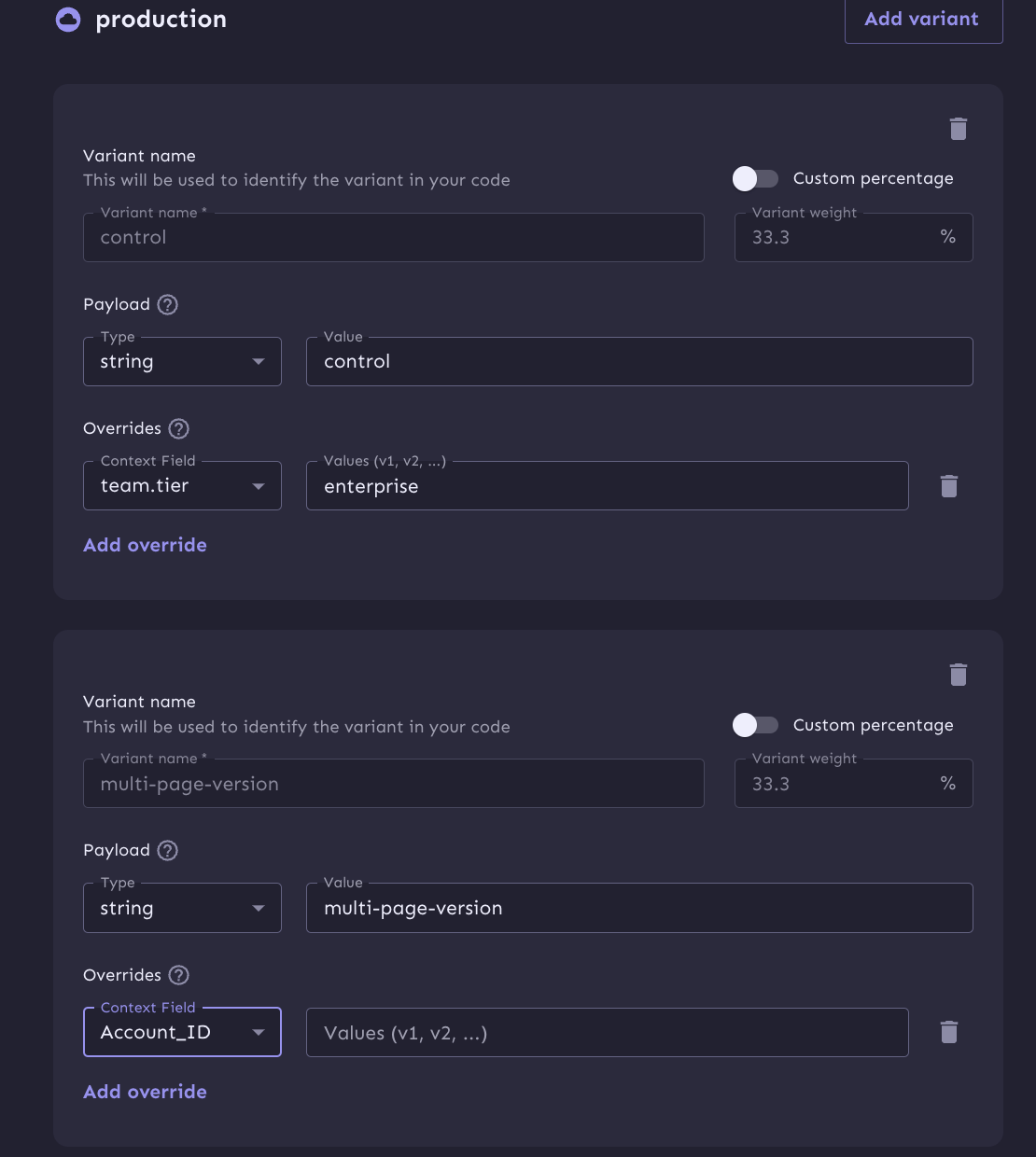
This works for our Enterprise tier which was a simple property match.
But for our beta-group this functionality doesn't allow us to use our shared segments.
For the user.email, we aren't able to use an ends-with operator on this screen. We can only use an equality match.
So Unleash passes on the team-tier and fails on the other two.
The last note on UI here is that overview page here is, in my subjective opinion, confusing.
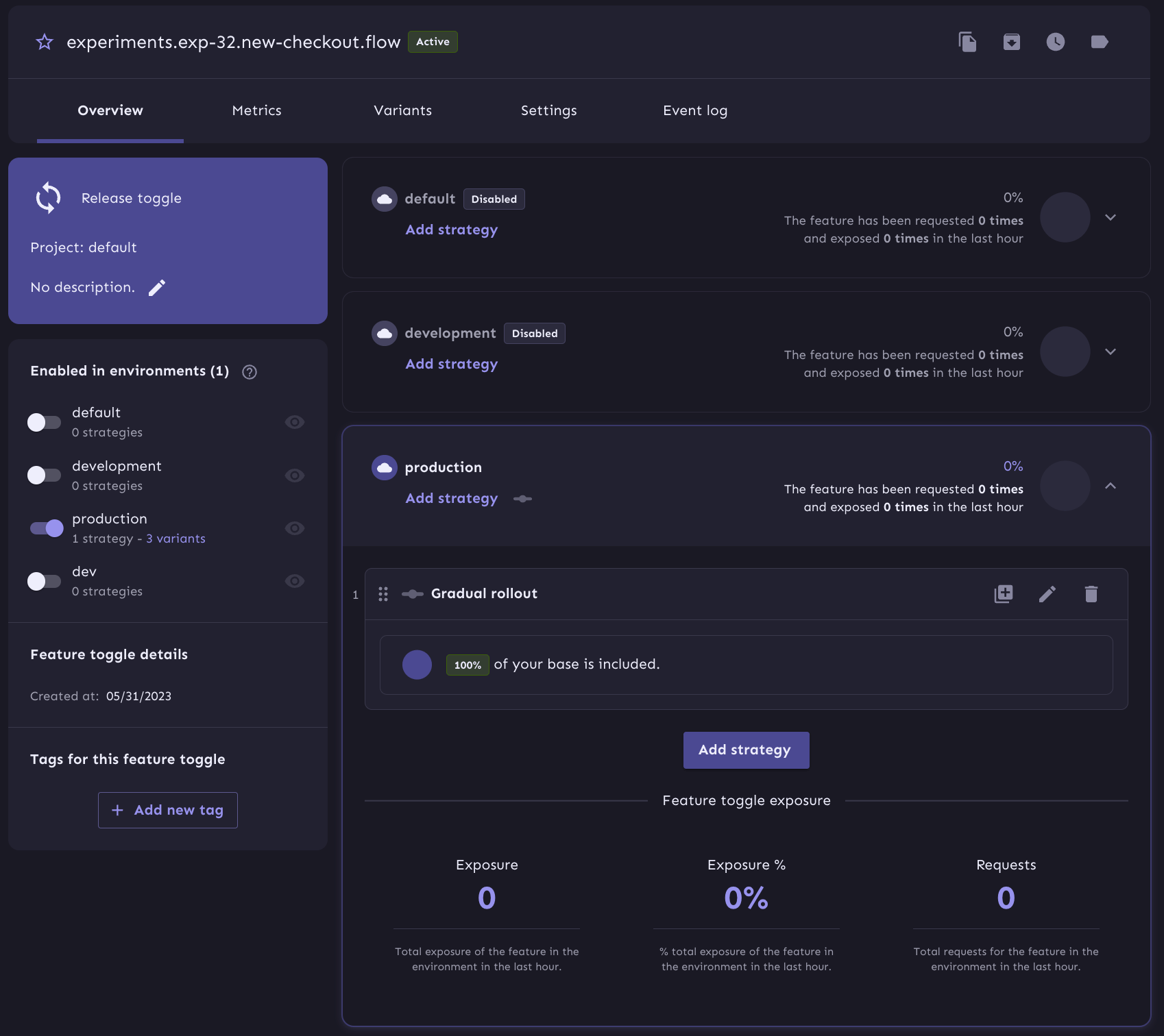 It's very hard to understand what's going on because the logic is split between
the rules and variant pages. And if we dive into the variants page, we still can't see the
overrides without going to the edit screen.
It's very hard to understand what's going on because the logic is split between
the rules and variant pages. And if we dive into the variants page, we still can't see the
overrides without going to the edit screen.

Unleash Takeaways
- Best for: Privacy / EU Compliance.
- Price: Starts at $80 per month for 5 users.
- Test Case: 😐 Challenges with targeting UI.
- Architecture: Interesting architecture supporting enhanced privacy because customer data stays on-premises or in cloud proxies you run.
- Notes:
- Problematic targeting UI doesn't pass our test case.
- No streaming updates, polling only.
- Nice Demo instance you can play with.
Prefab
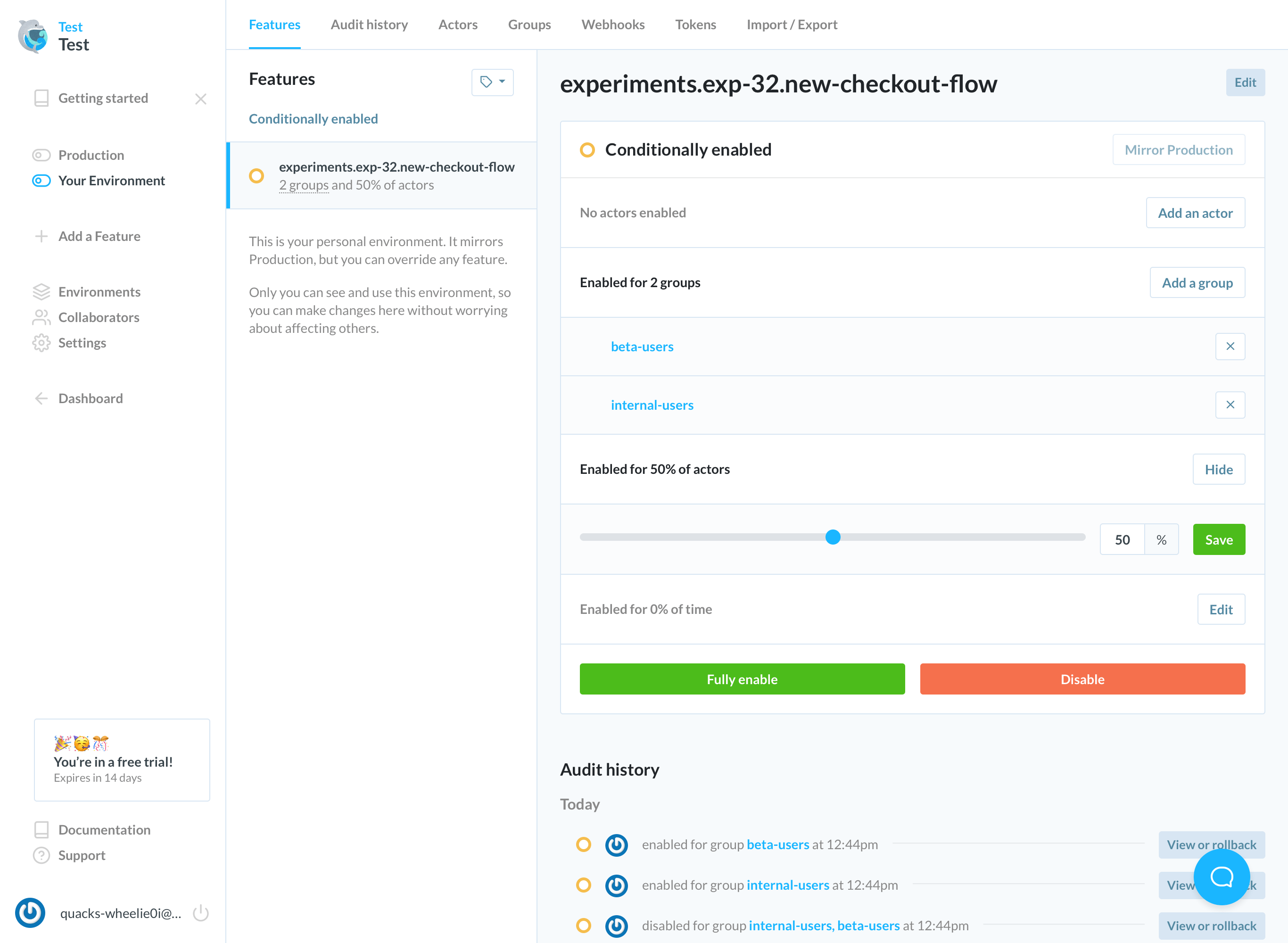
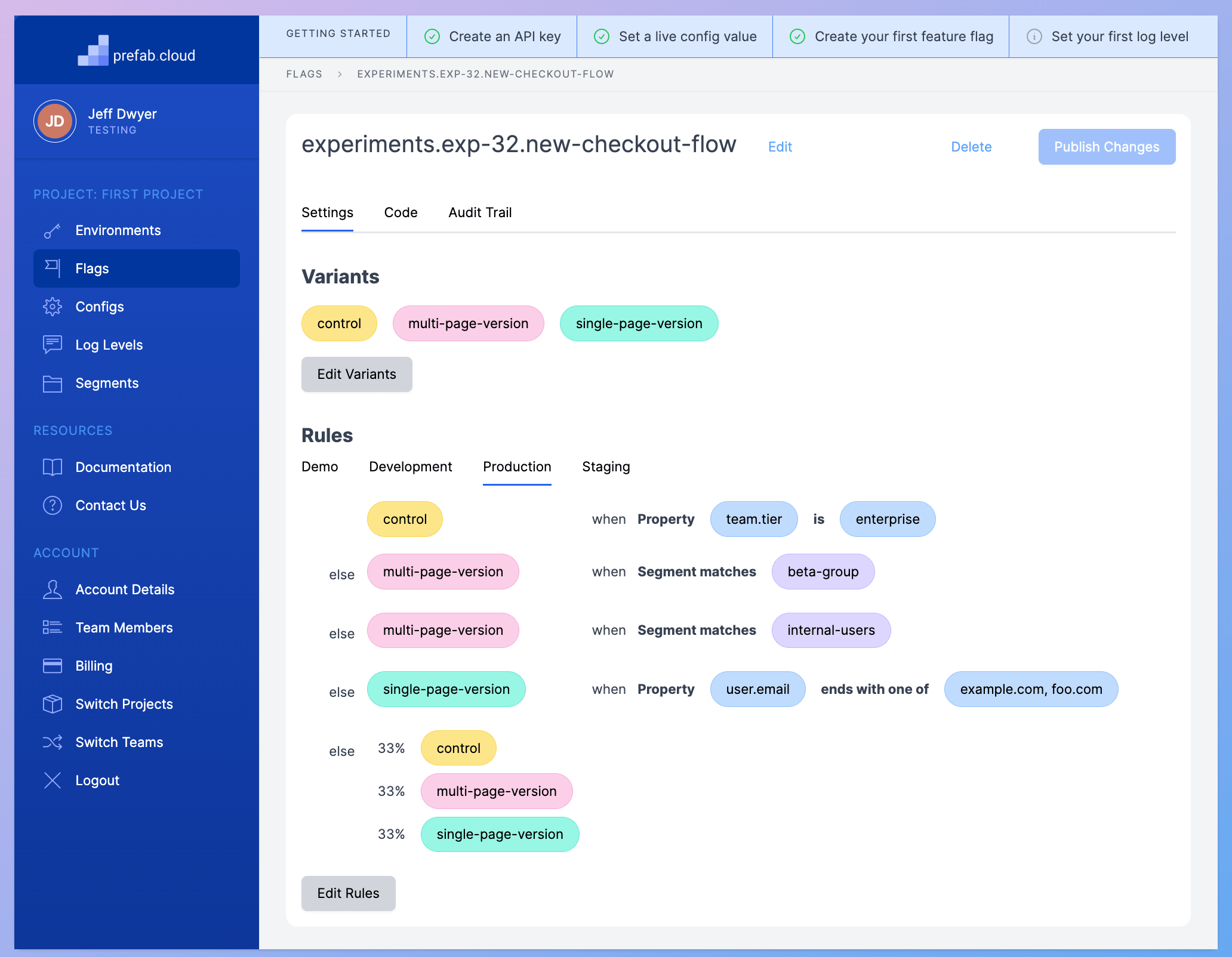
Prefab is a newer entrant into the FeatureFlag market. I'm biased, but I think it passed the test with flying colors.
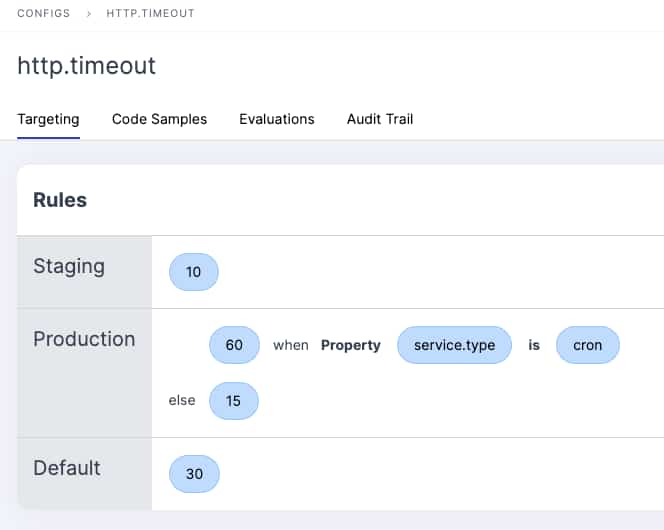
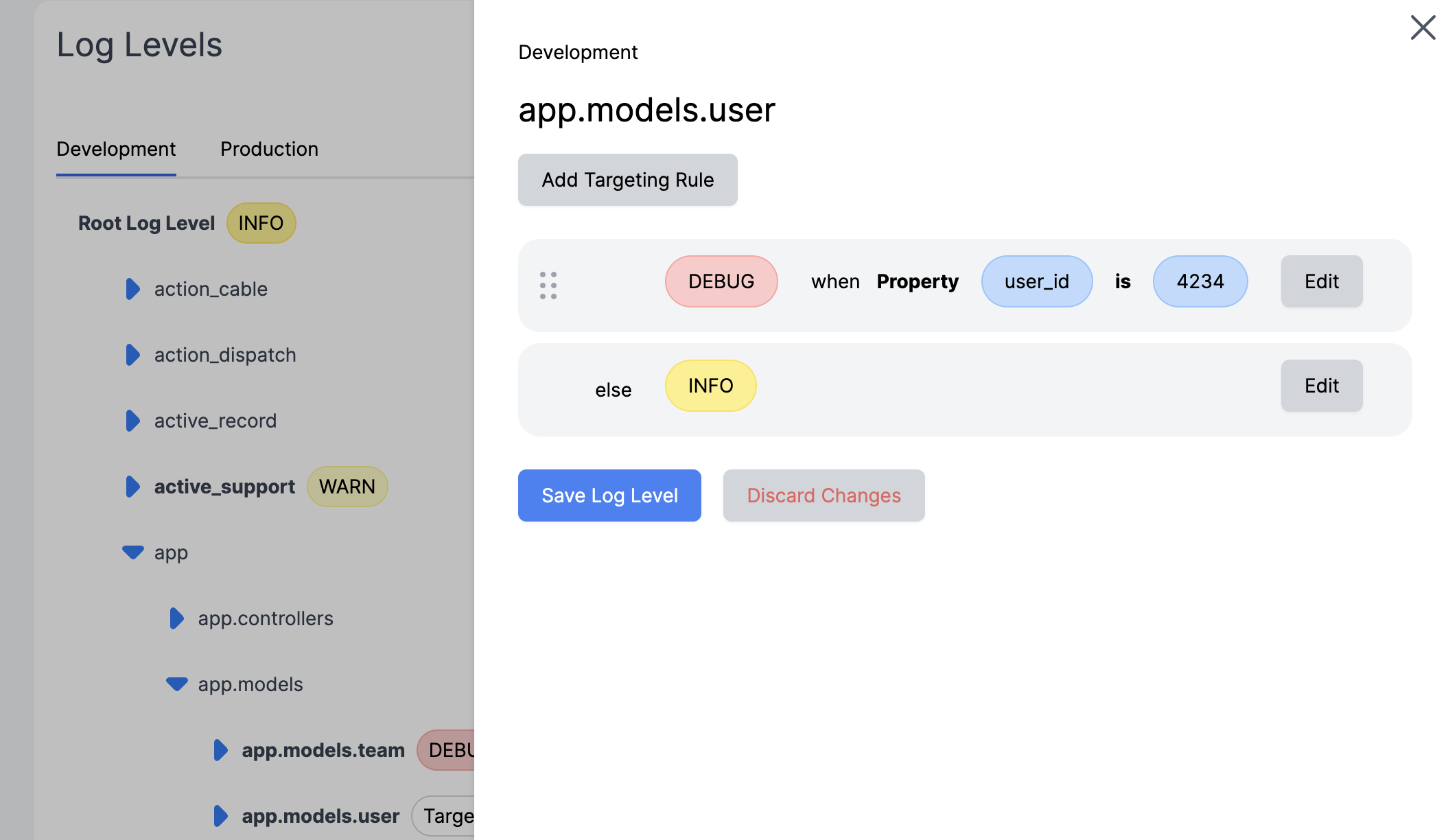
- We are able to define the 3 variants for our flag.
- We can setup a property match for the enterprise tier.
- We can use shared segments to target the beta and internal customers.
- We can do a 33% rollout across the rest of our customers.
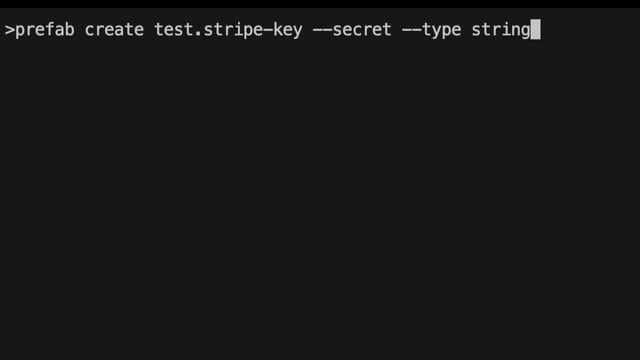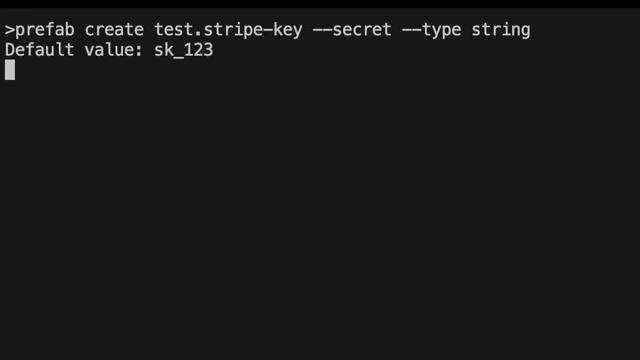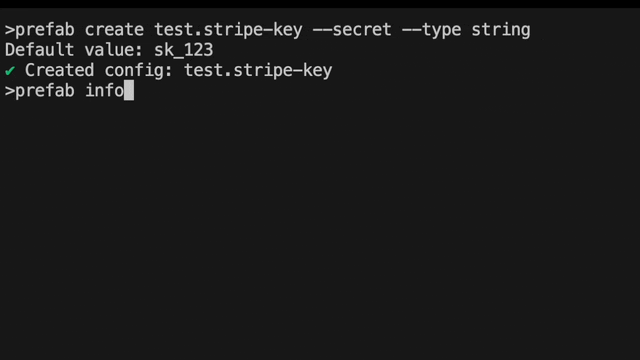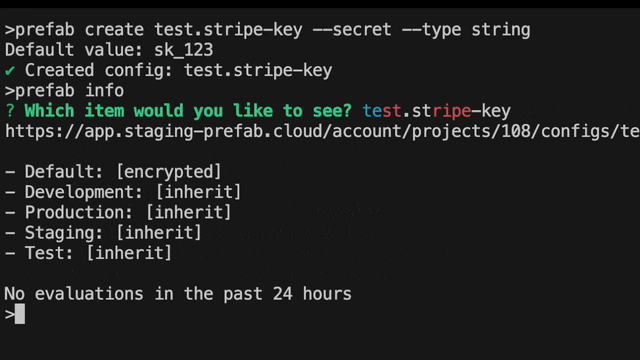
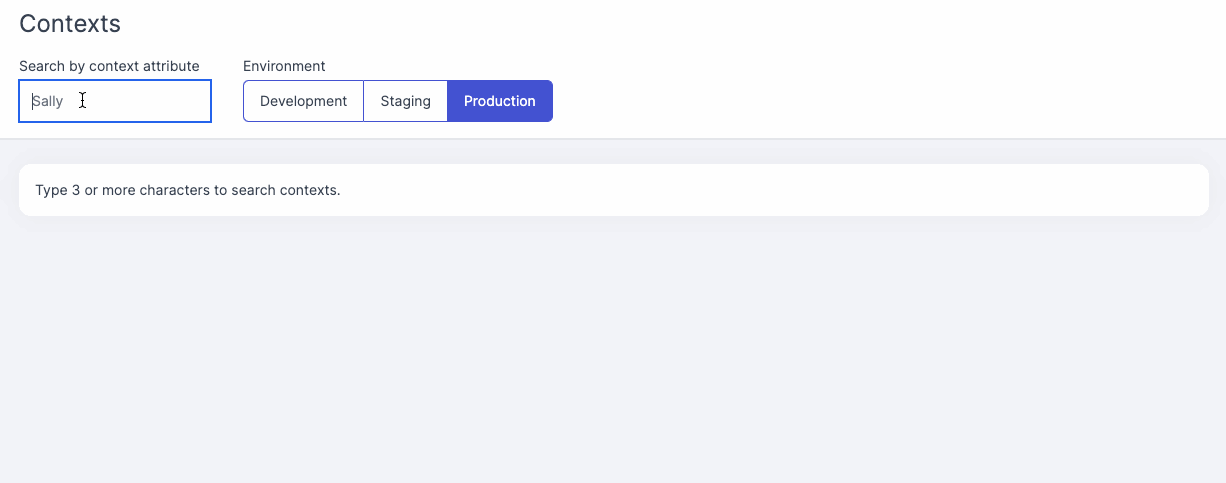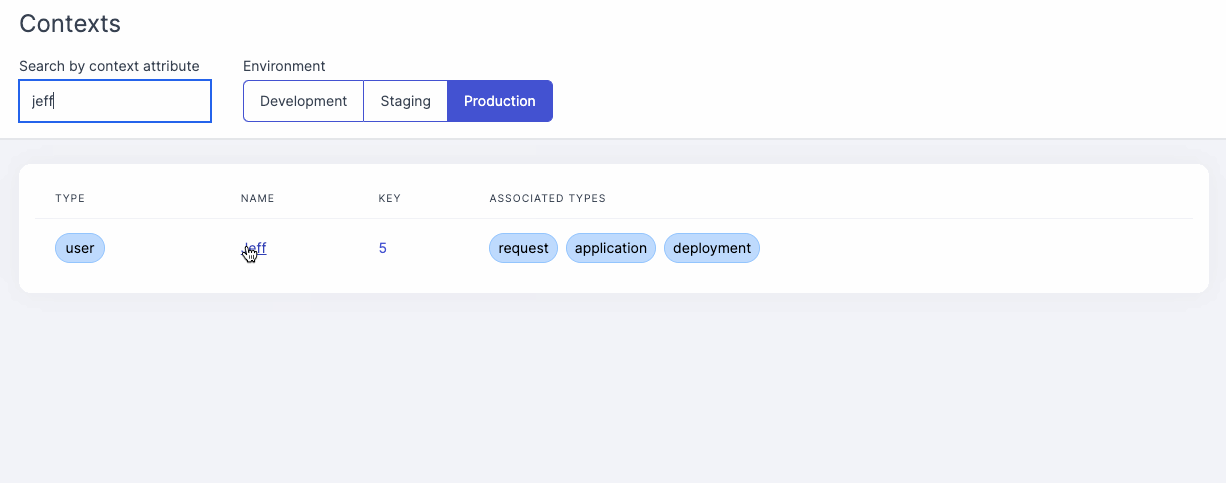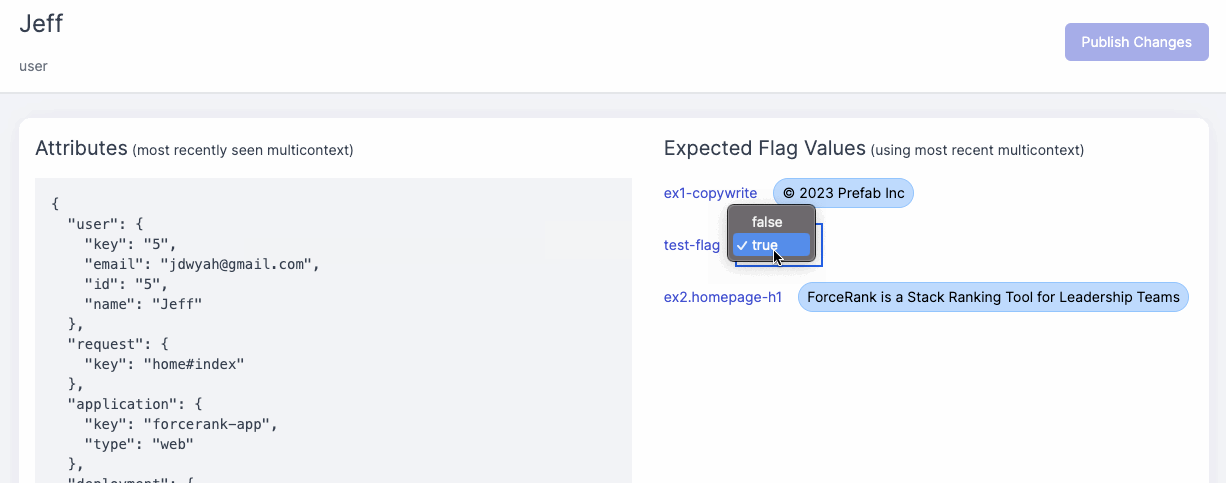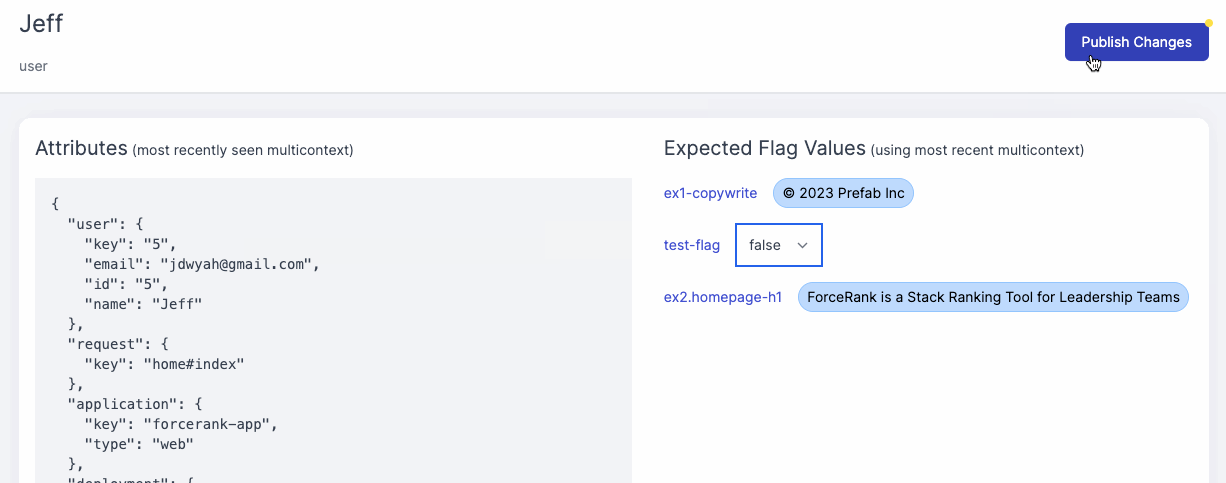
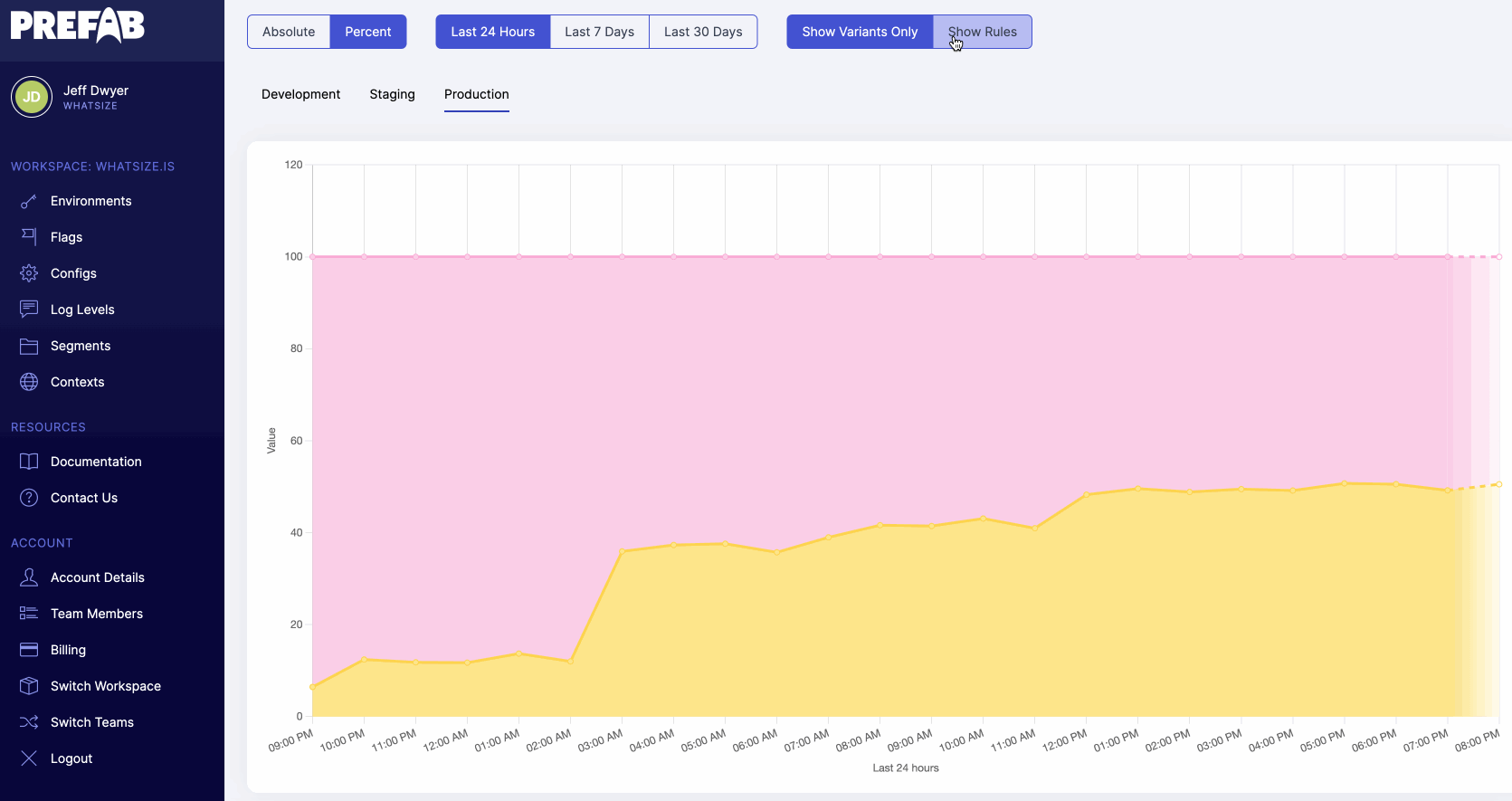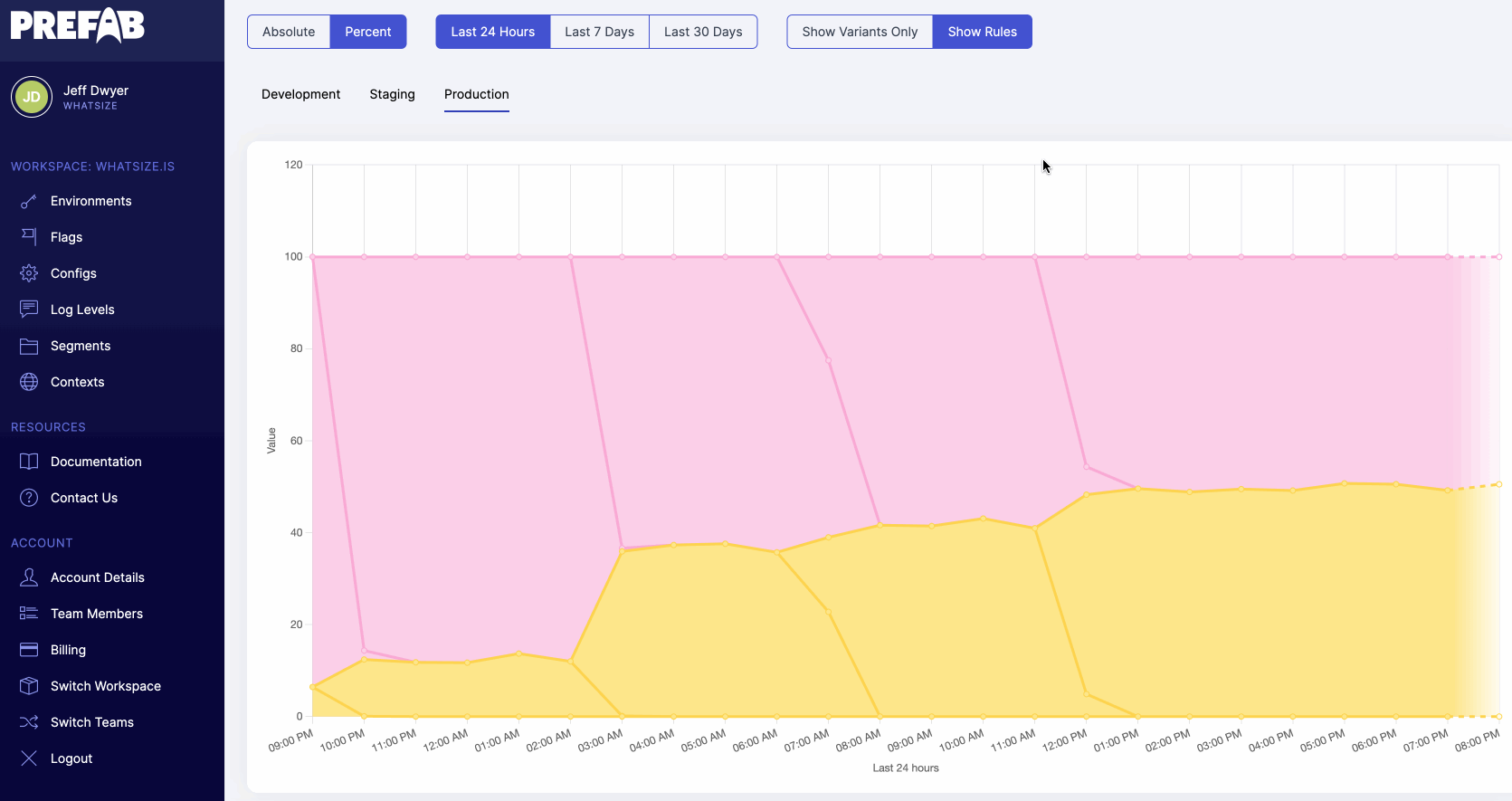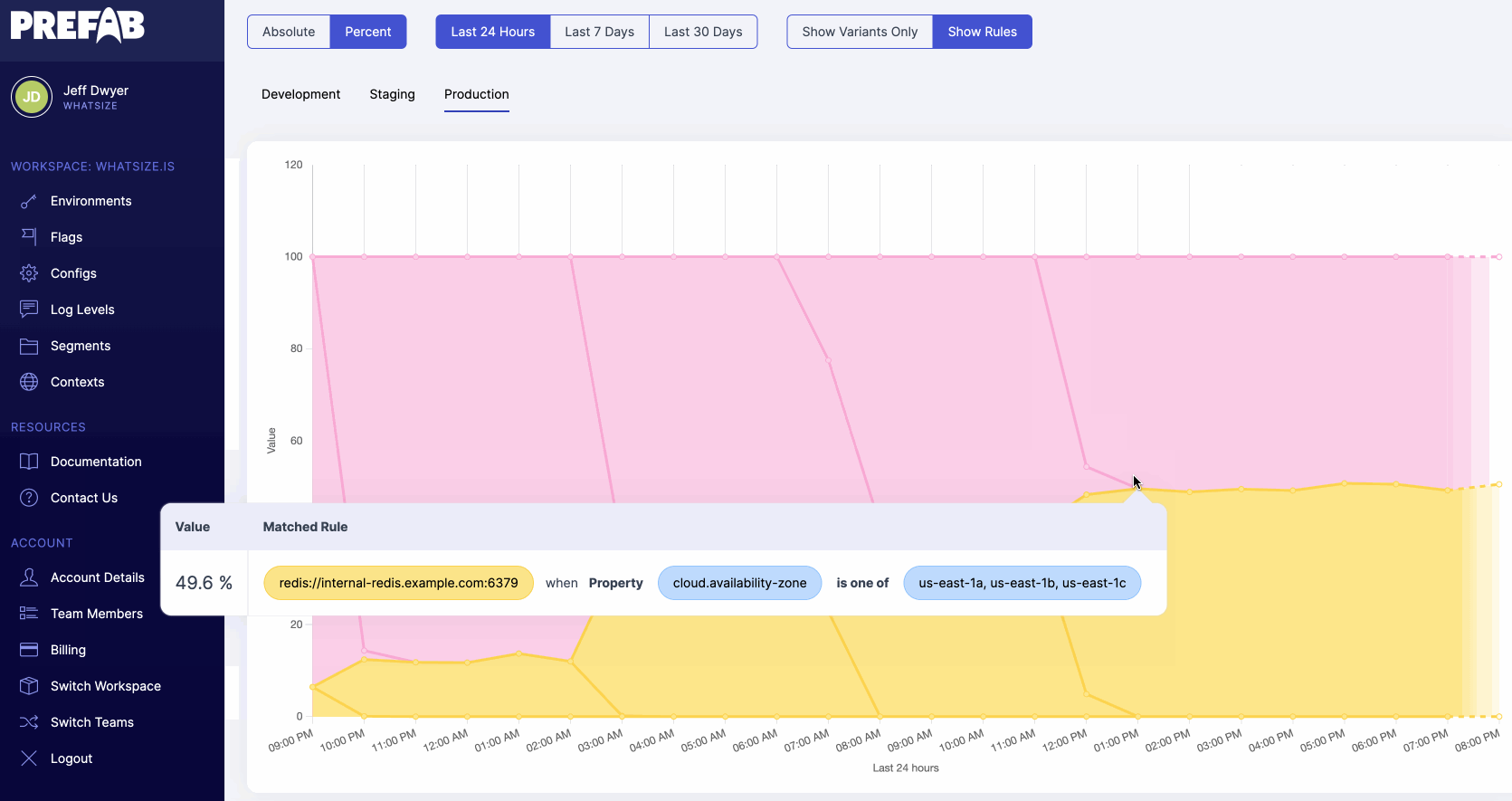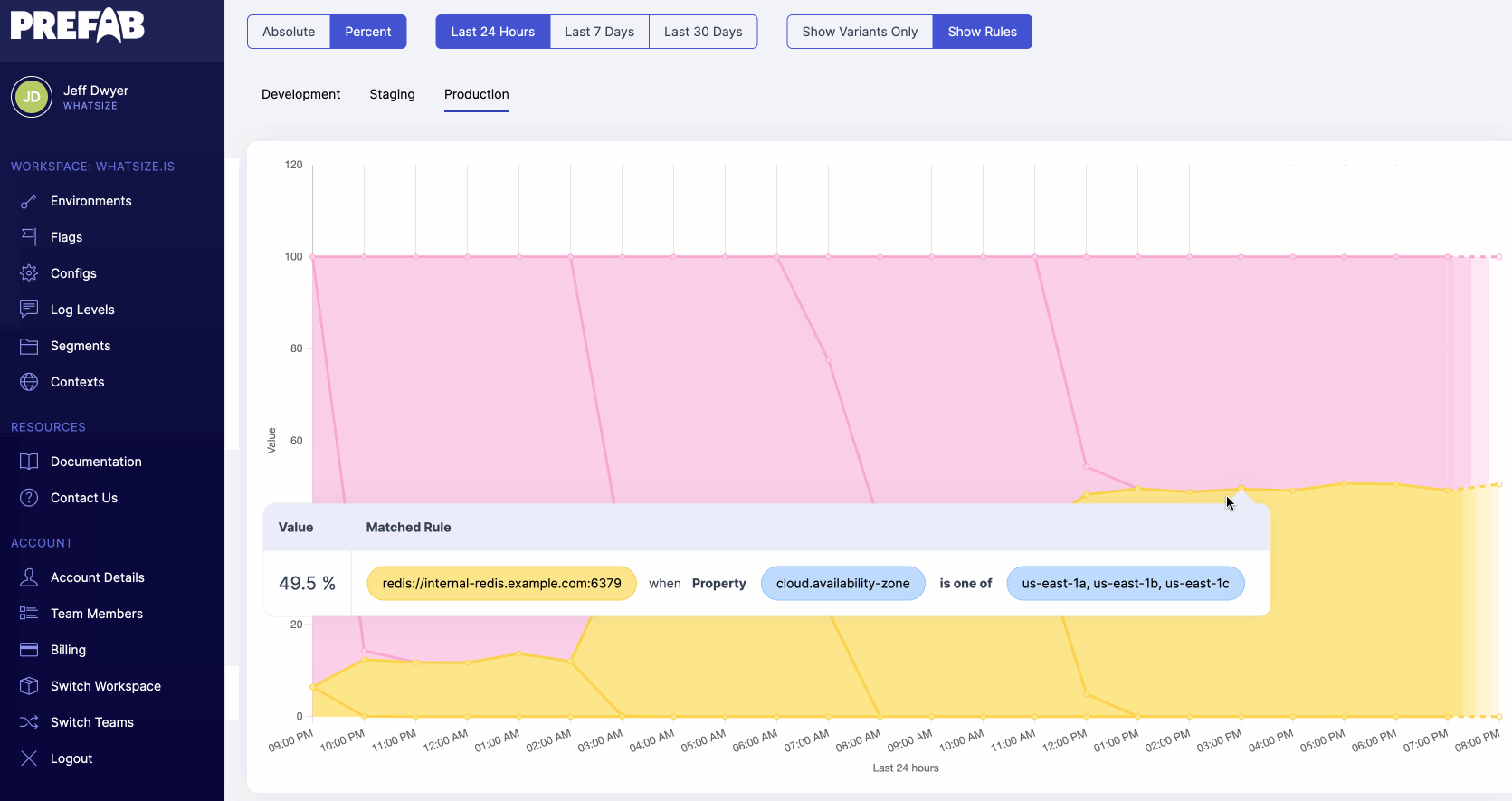
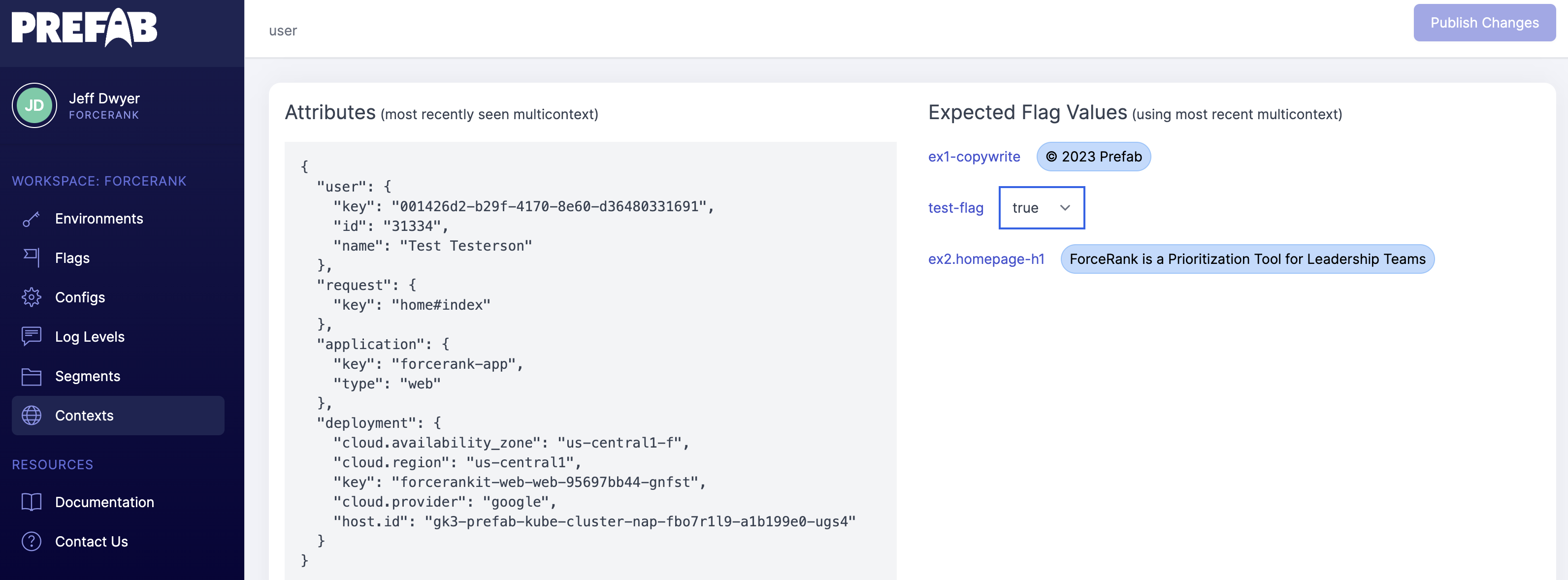
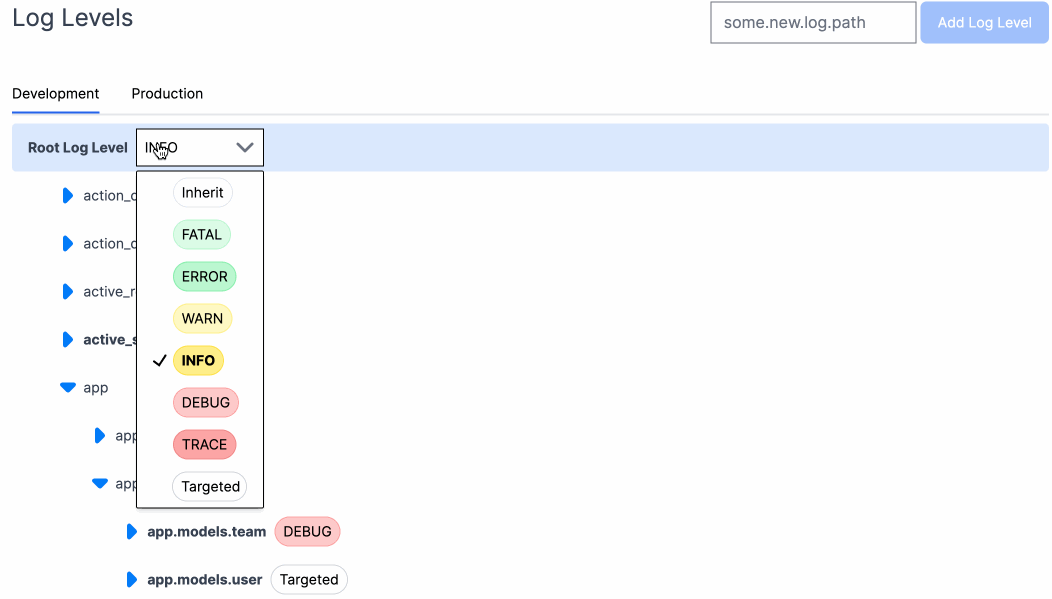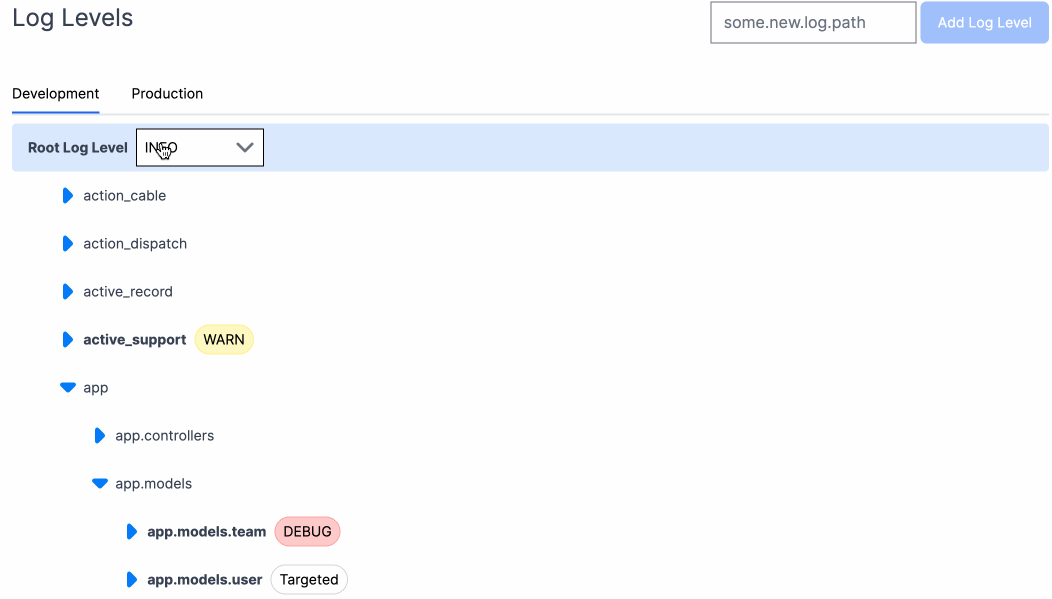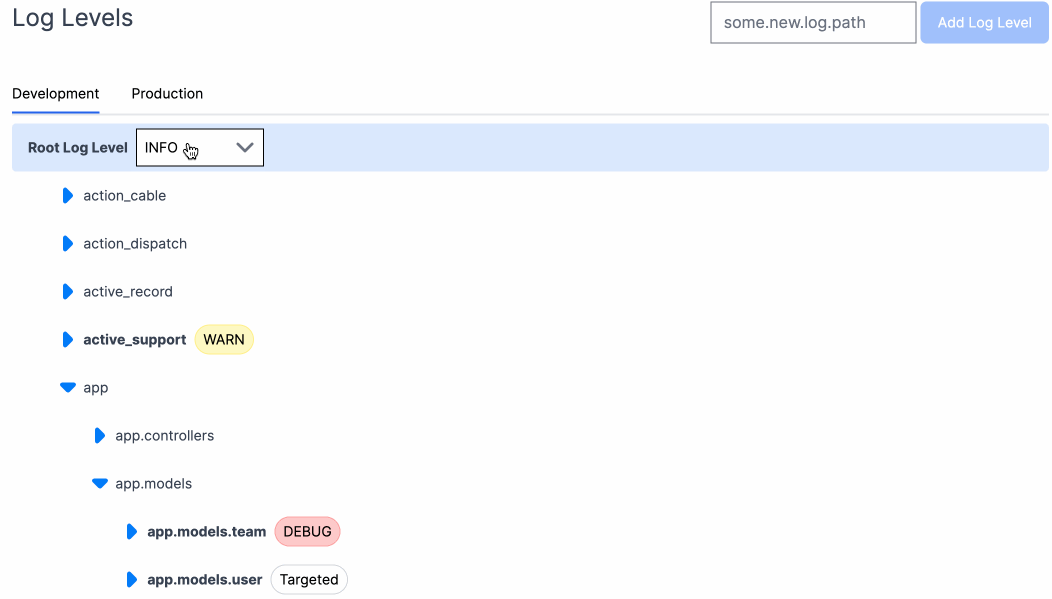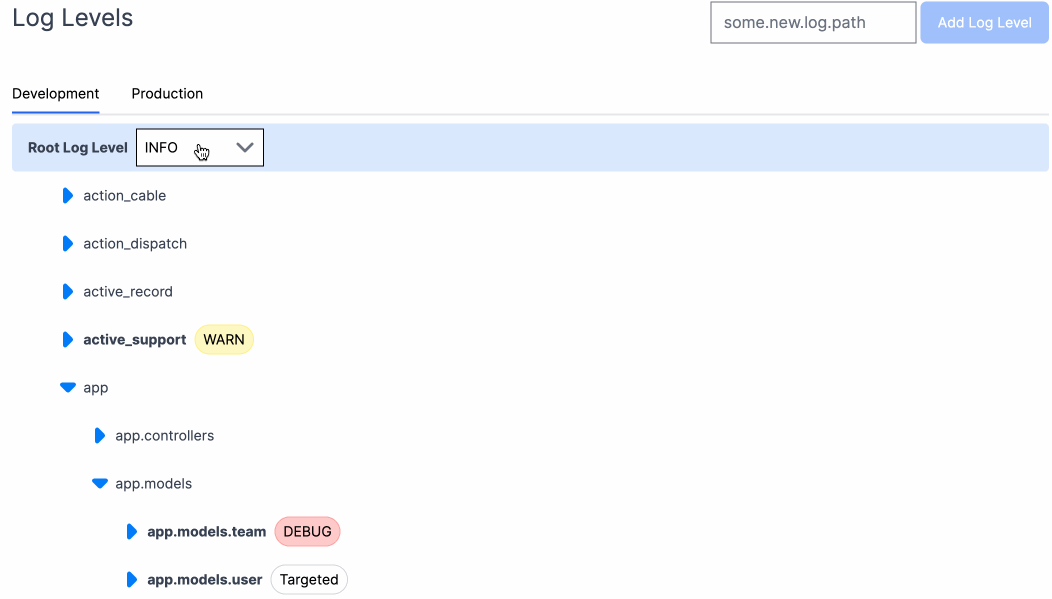
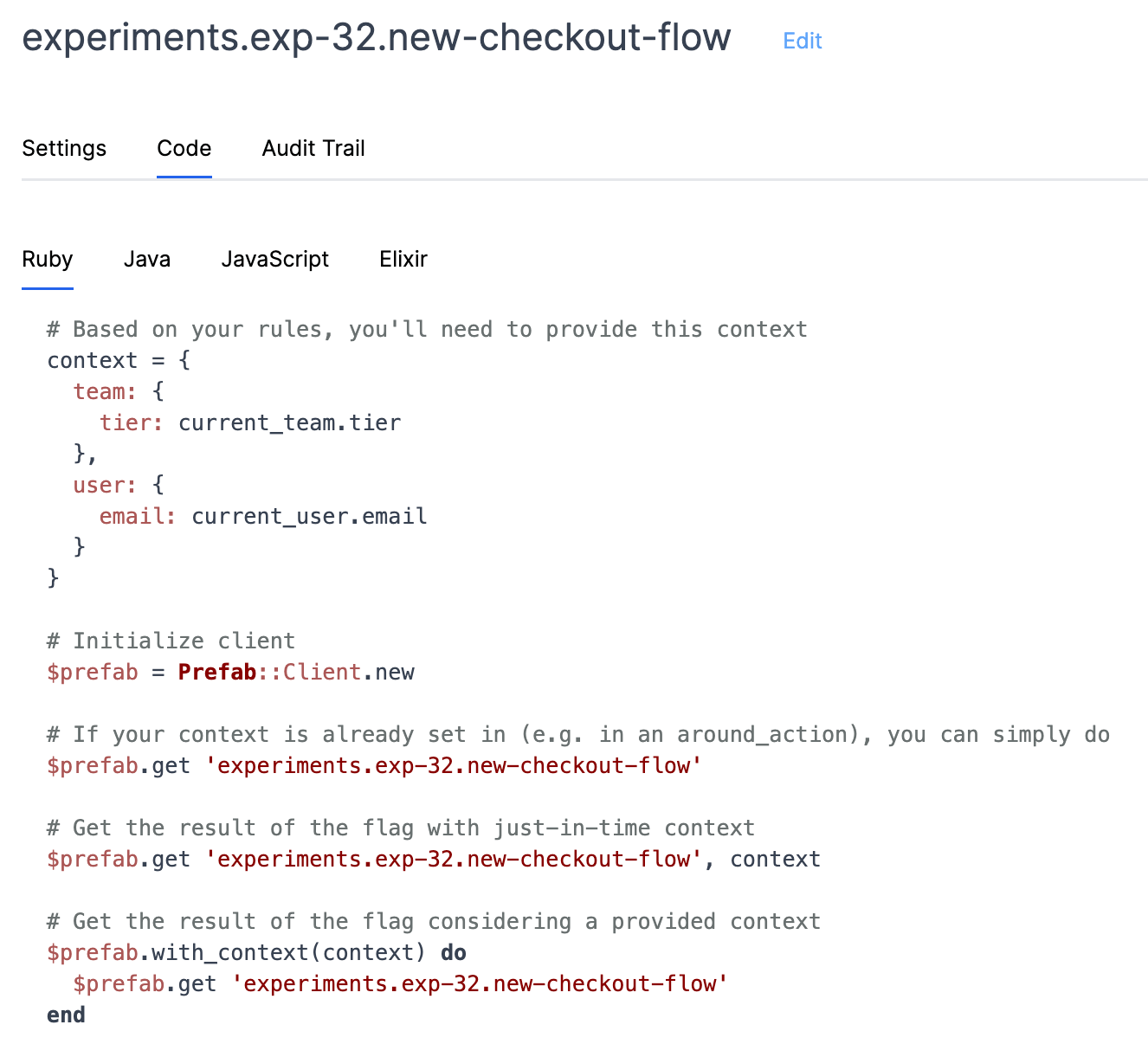
Prefab has a flexible context system that allows you to set context at the beginning of the request so you don't need to specify the context for every flag evaluation.
Prefab explains how to do this in the UI with helpful code suggestions. You can see the context you'll need to evaluate the flag.
Prefab Takeaways
- Best for: Teams looking for real-time updates, robust resiliency, and competitive pricing.
- Price: Super competitive pricing. $1 / pod charged minutely. $1 / 10k client MAU.
- Test Case: 😀 Strong Pass.
- Features: Robust audit logging, shared segments, real-time updates. Missing features: Full experimentation suite, reporting & advanced ACL / roles.
- Architecture: Server-side evaluation. Real-time updates with SSE. CDN backed reliability story.
- Notes:
- Clients in Ruby, Java, Node, Python, JS & React.
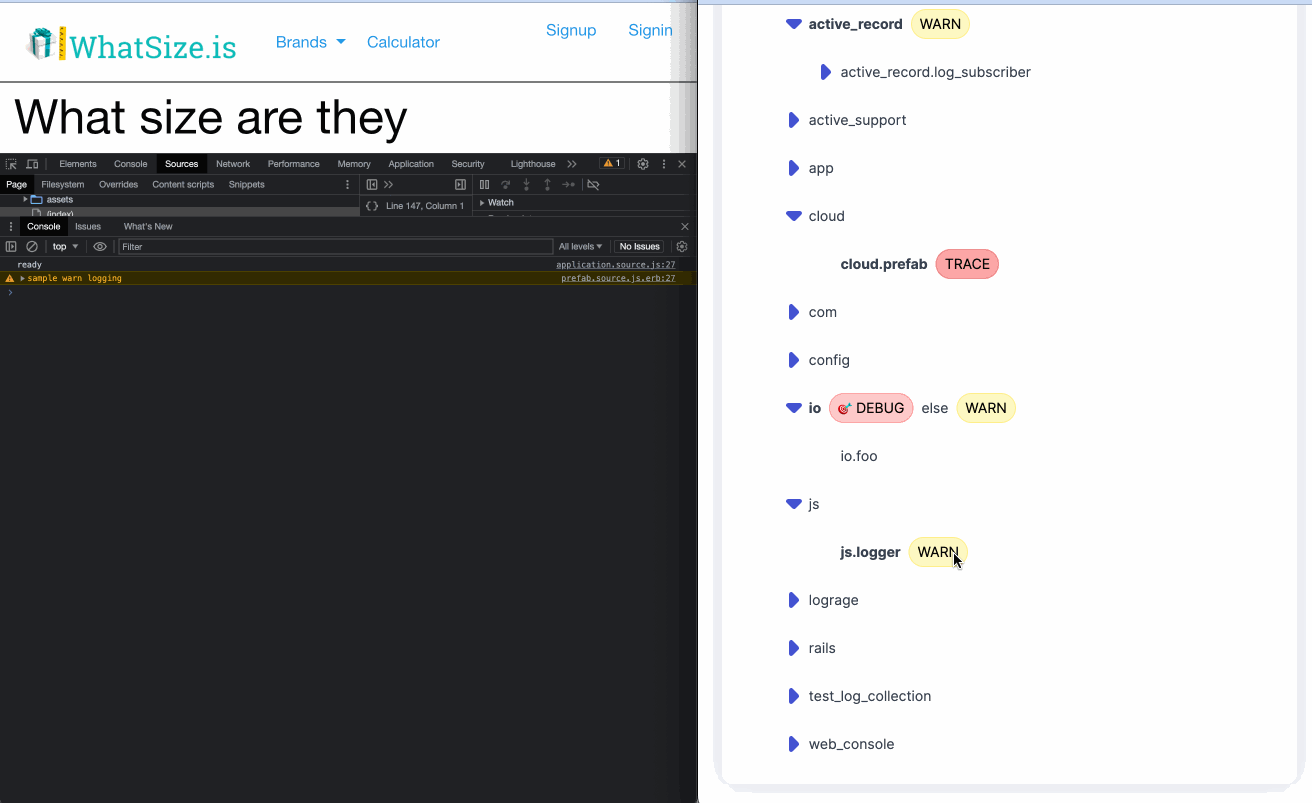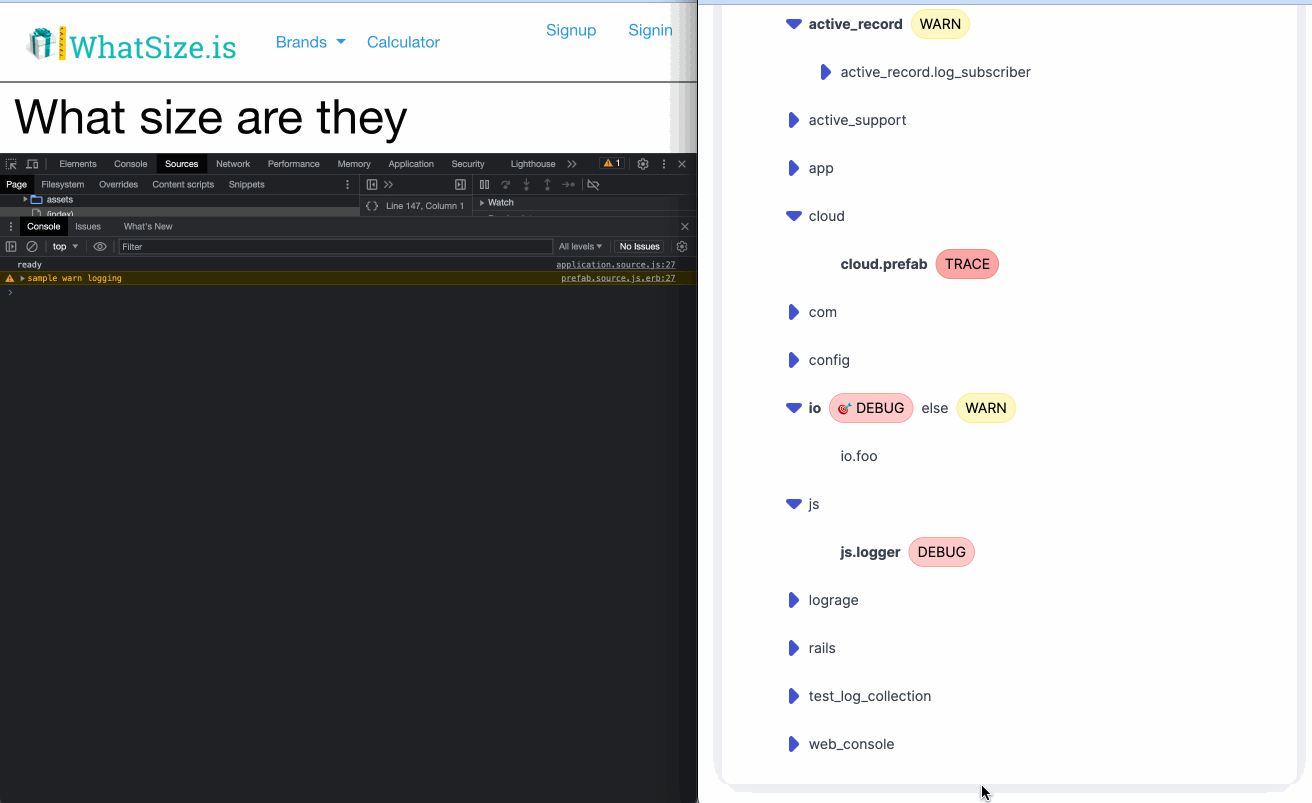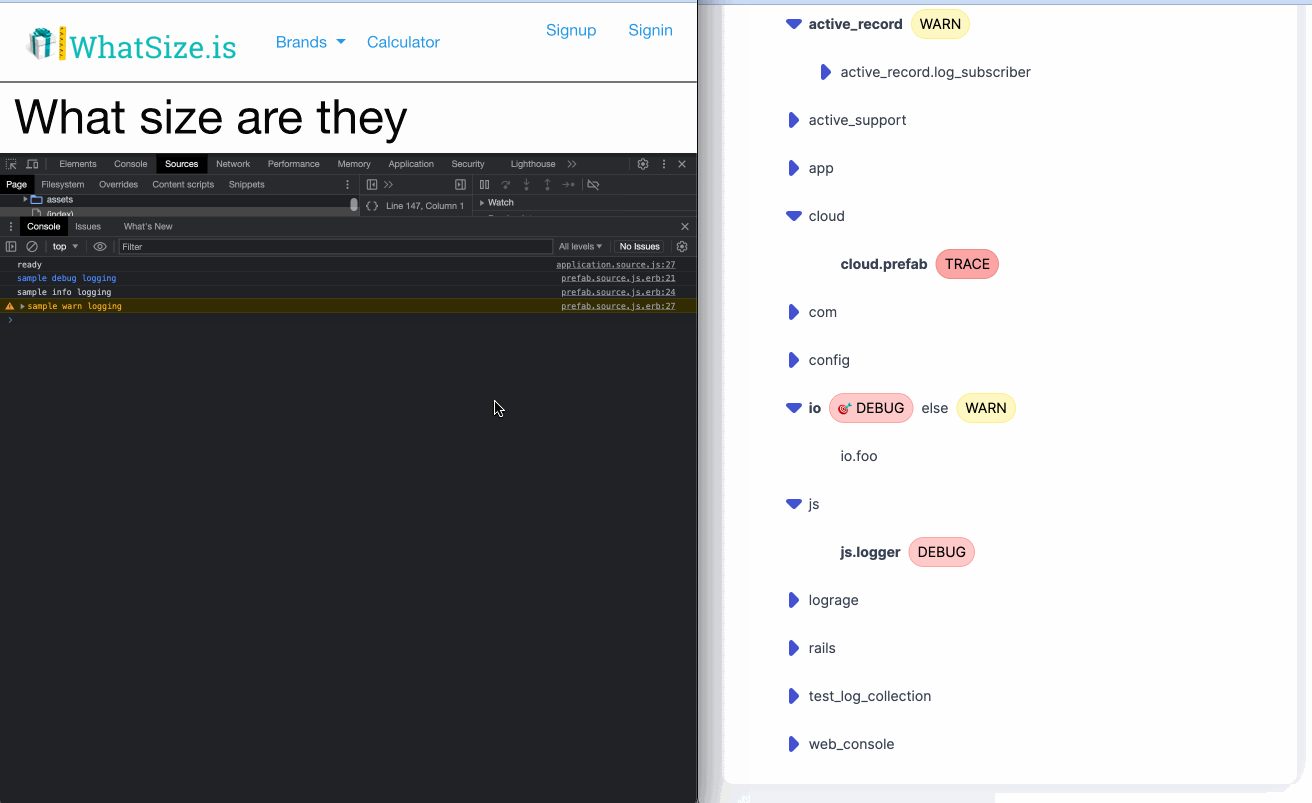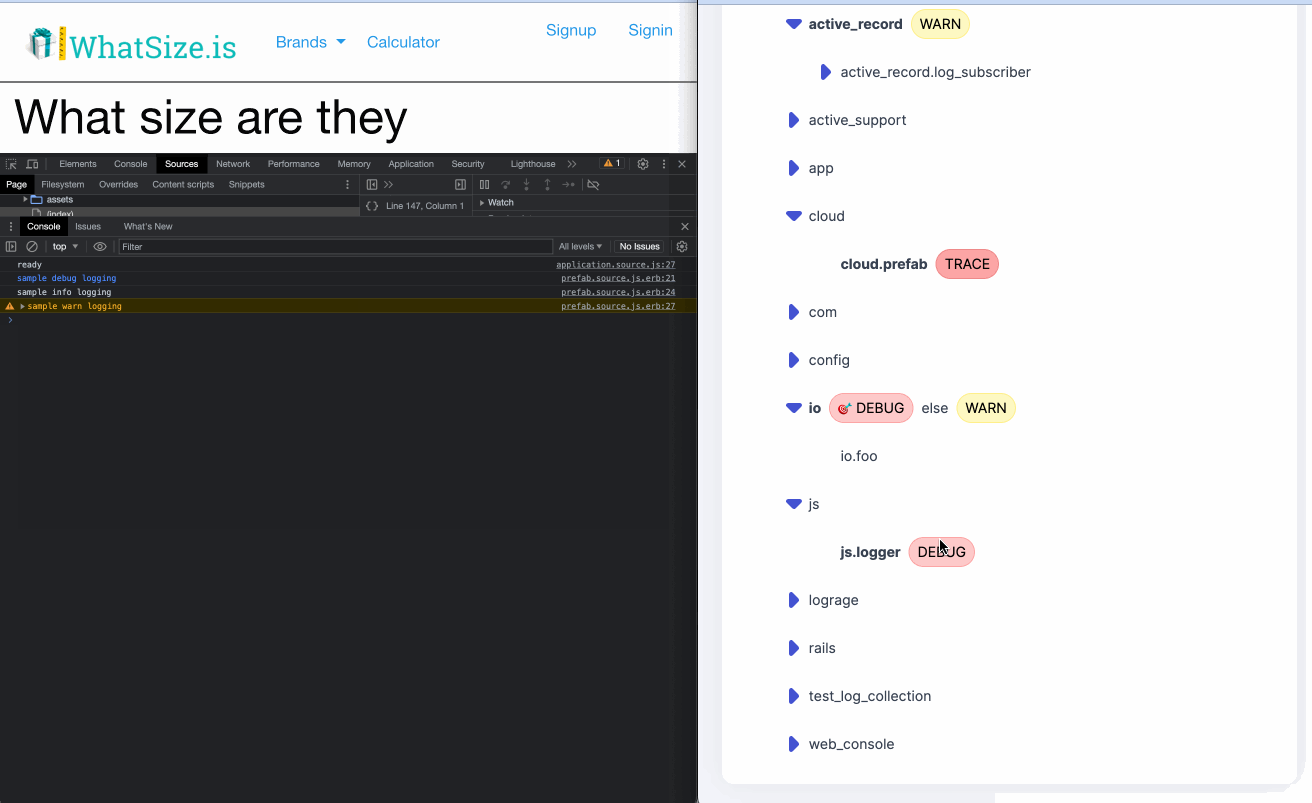
- Also provides other developer experience feature like dynamic log levels.
- Good story around local testing with default files.
Flagsmith
Our next comparison is with Flagsmith. Flagsmith is also open-source and
touts itself as a good option for cloud or on-premises deployments.
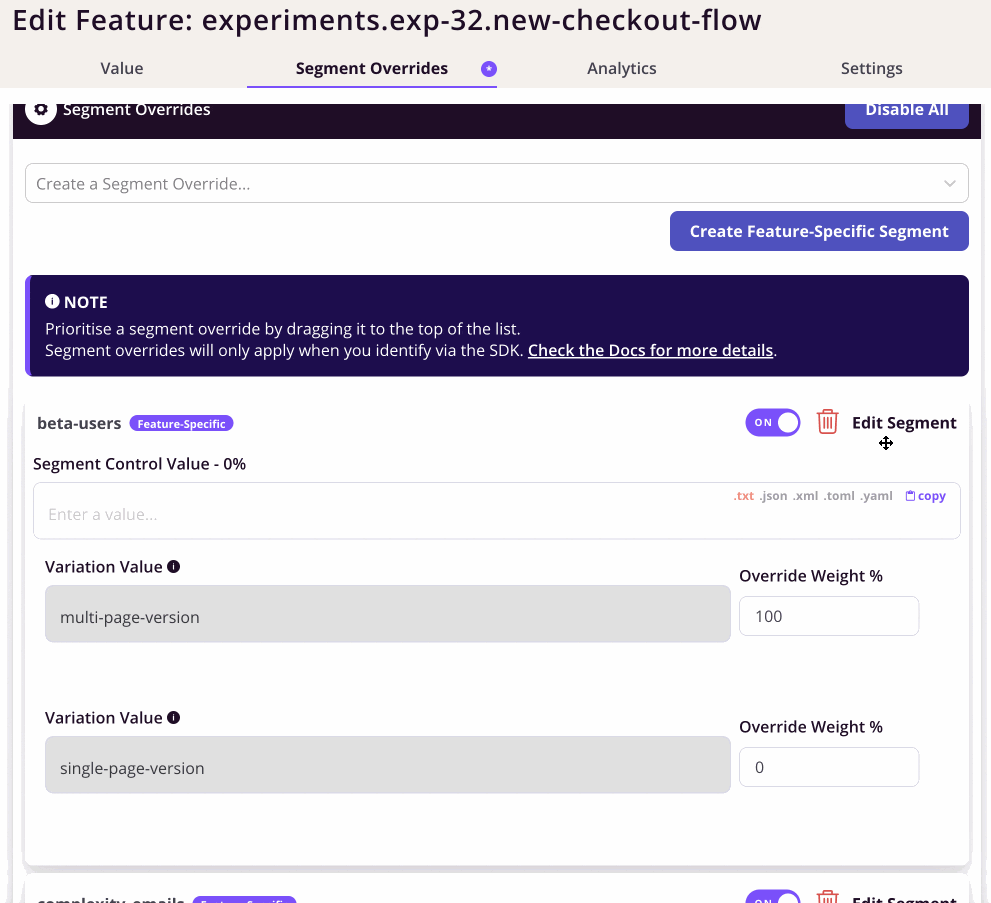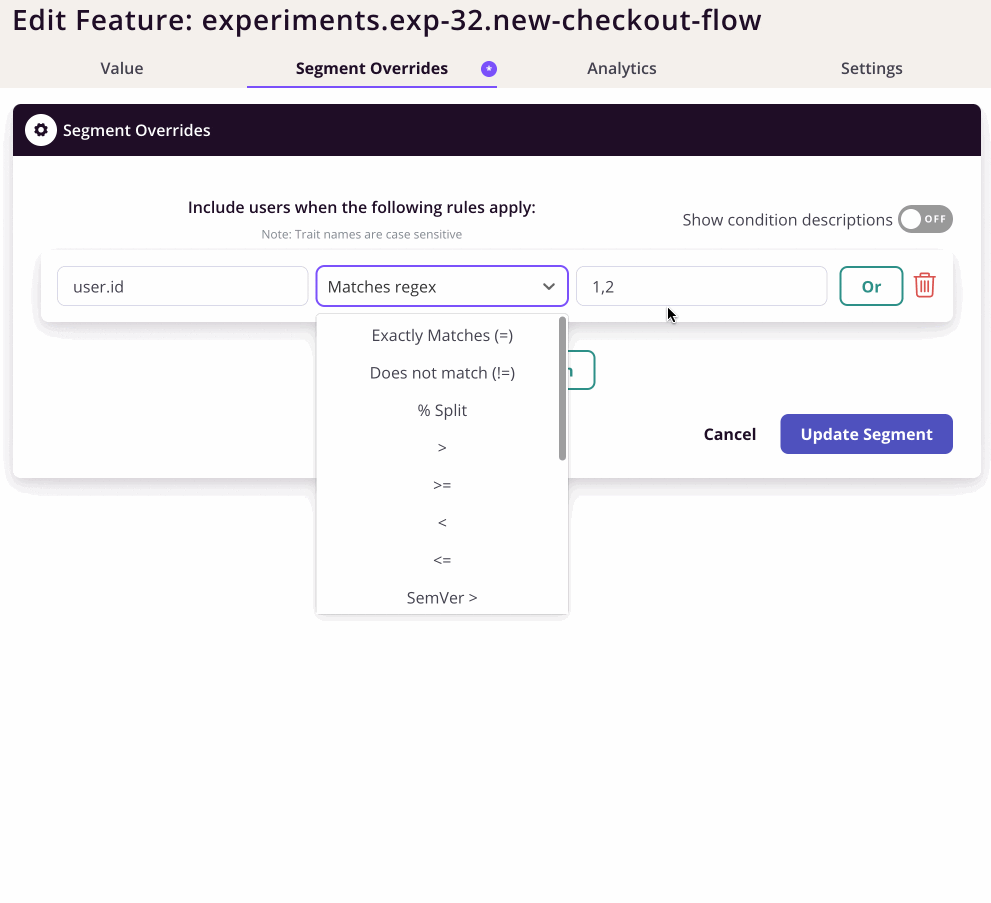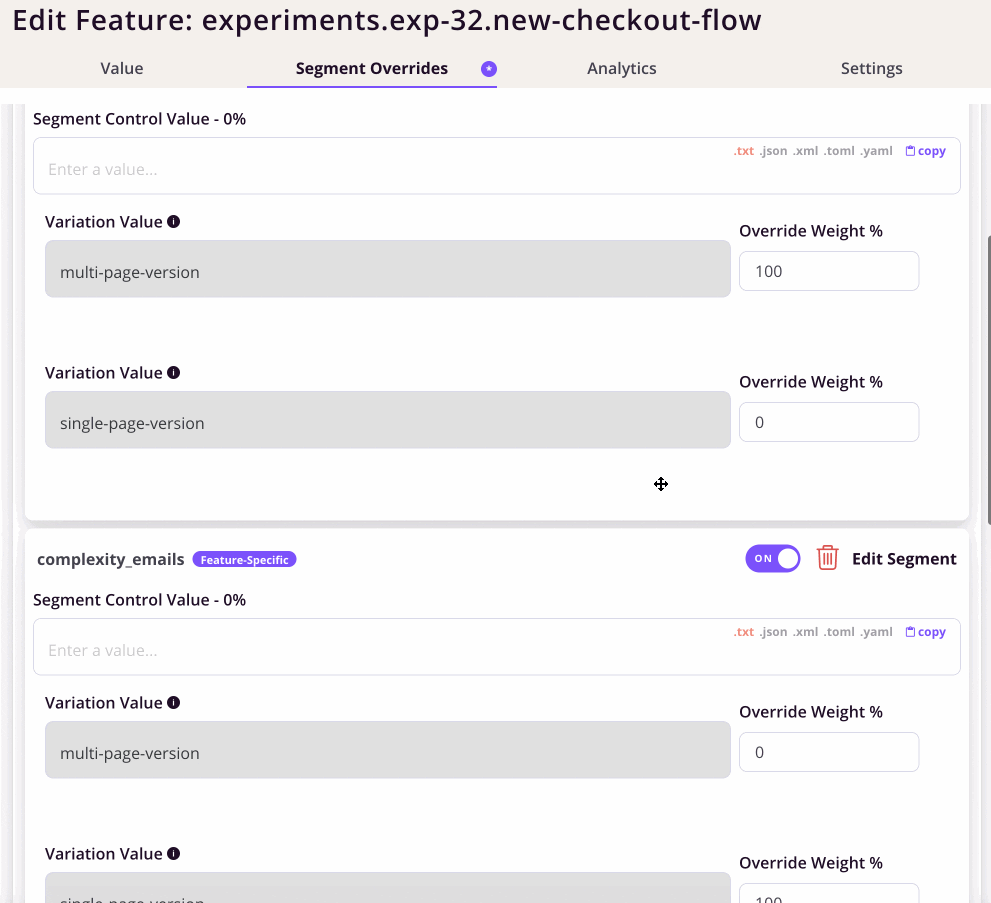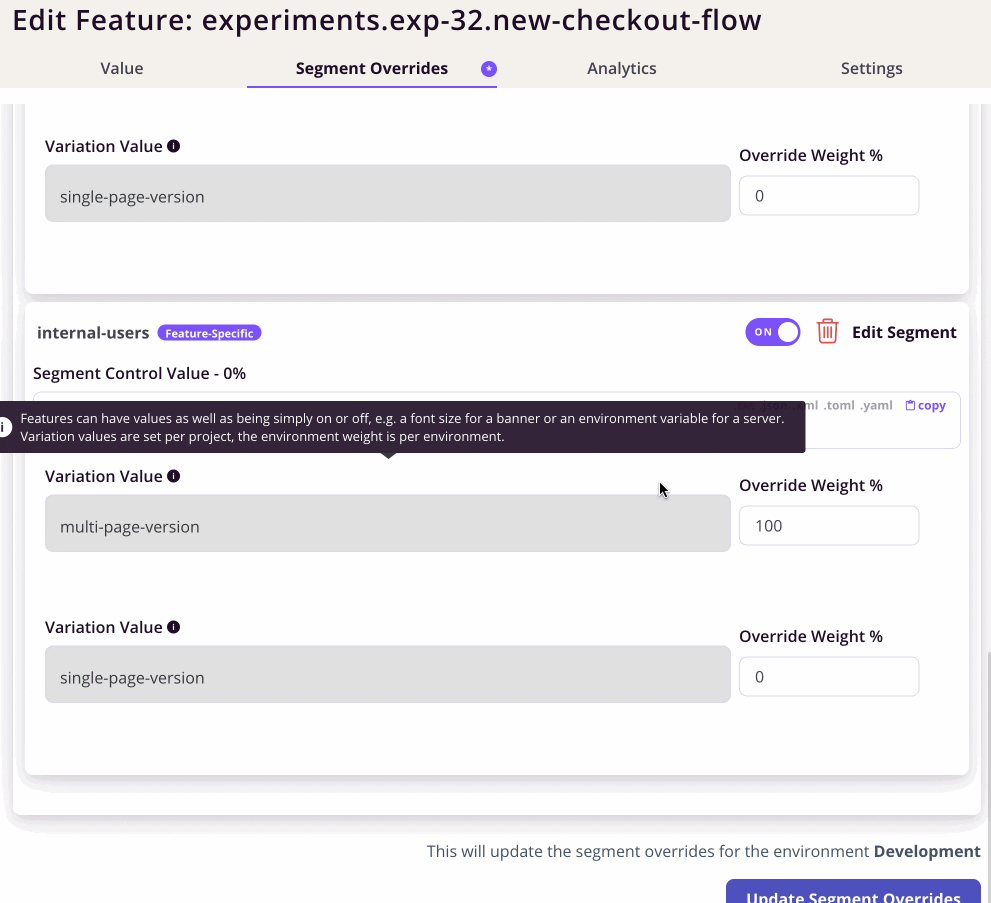
Flagsmith has good support for multivariate flags, so that's a relief.
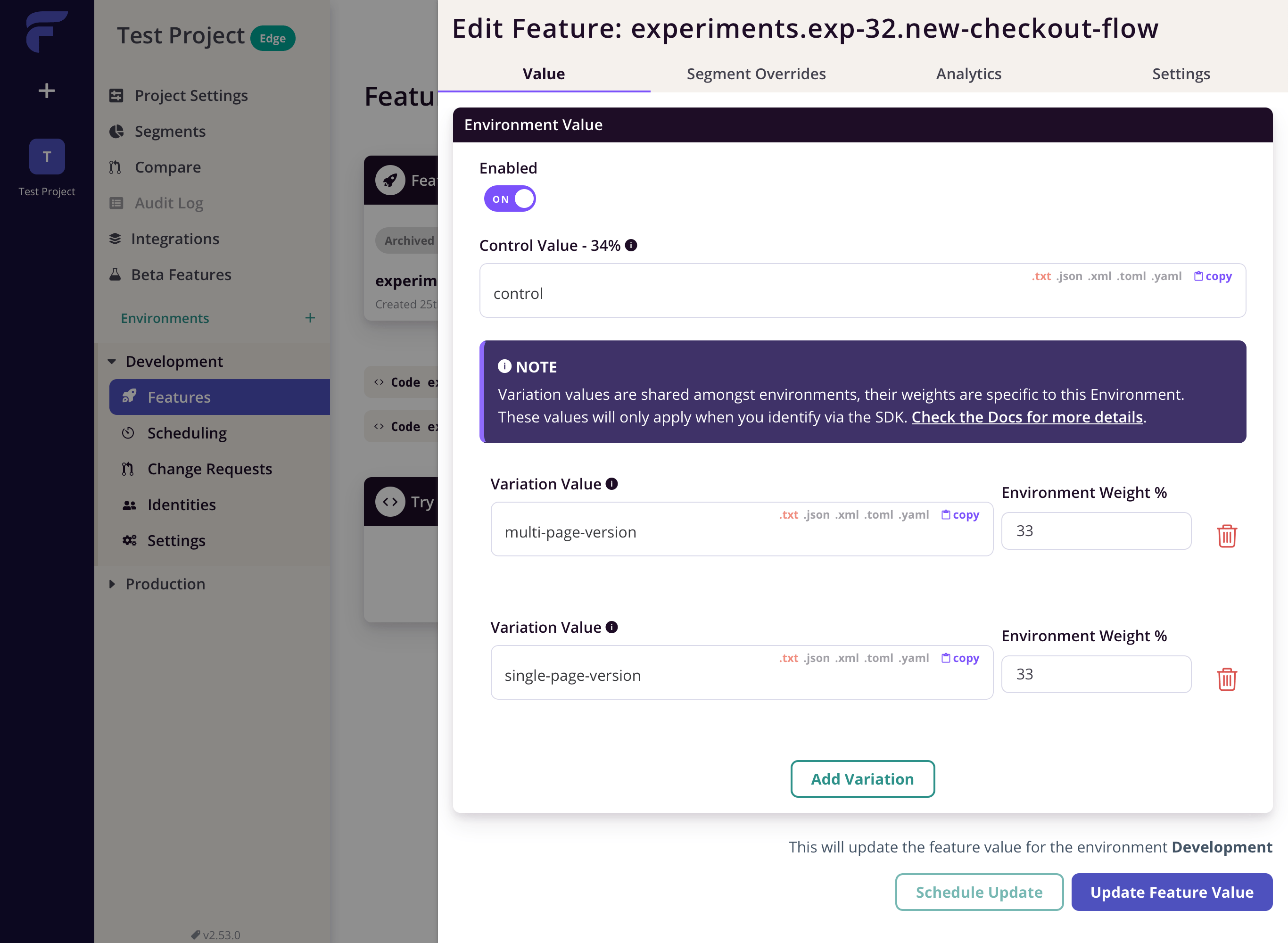
The actual overrides is interesting. We specify rules and then specify the weights for each variant.
This worked, but lead to a very long page of rules.
I also found the UI unclear for how to create the beta group. If I want the beta group to be user.id 1 or 2. It wasn't clear to me whether to use = and comma-delimit or use a regex.
- Best for: Flexible deployments & on-premises hosting.
- Price: Starts from $45 for 3 users per month. A free version with limited functionalities for a single user is available.
- Test Case: Strong Pass 😃 Shared Segments and multivariate support.
- Features: Shared Segments. Remote configs, A/B testing, integration with popular analytics engines.
- Architecture: Open source, provides hosted API for easier deployment during development cycles.
- Notes:
- Flag targeting is split across multiple UI tabs, can make it difficult to get an overview of flag settings.
- Targeting individual users only available on higher plan tier.
- No streaming updates, polling only.
LaunchDarkly
LaunchDarkly is a well known name in the feature flagging space. They have a robust feature set and a strong focus on enterprise customers. Let's see how they do with our test case.
Unsurprisingly LaunchDarkly does a great job of handling our test case. We can setup a property match for the enterprise tier, a shared segment for the beta group and internal users, and a user attribute for the email.
The UI is powerful, and you can see some of the more advanced enterprise features like workflows and prerequisites.
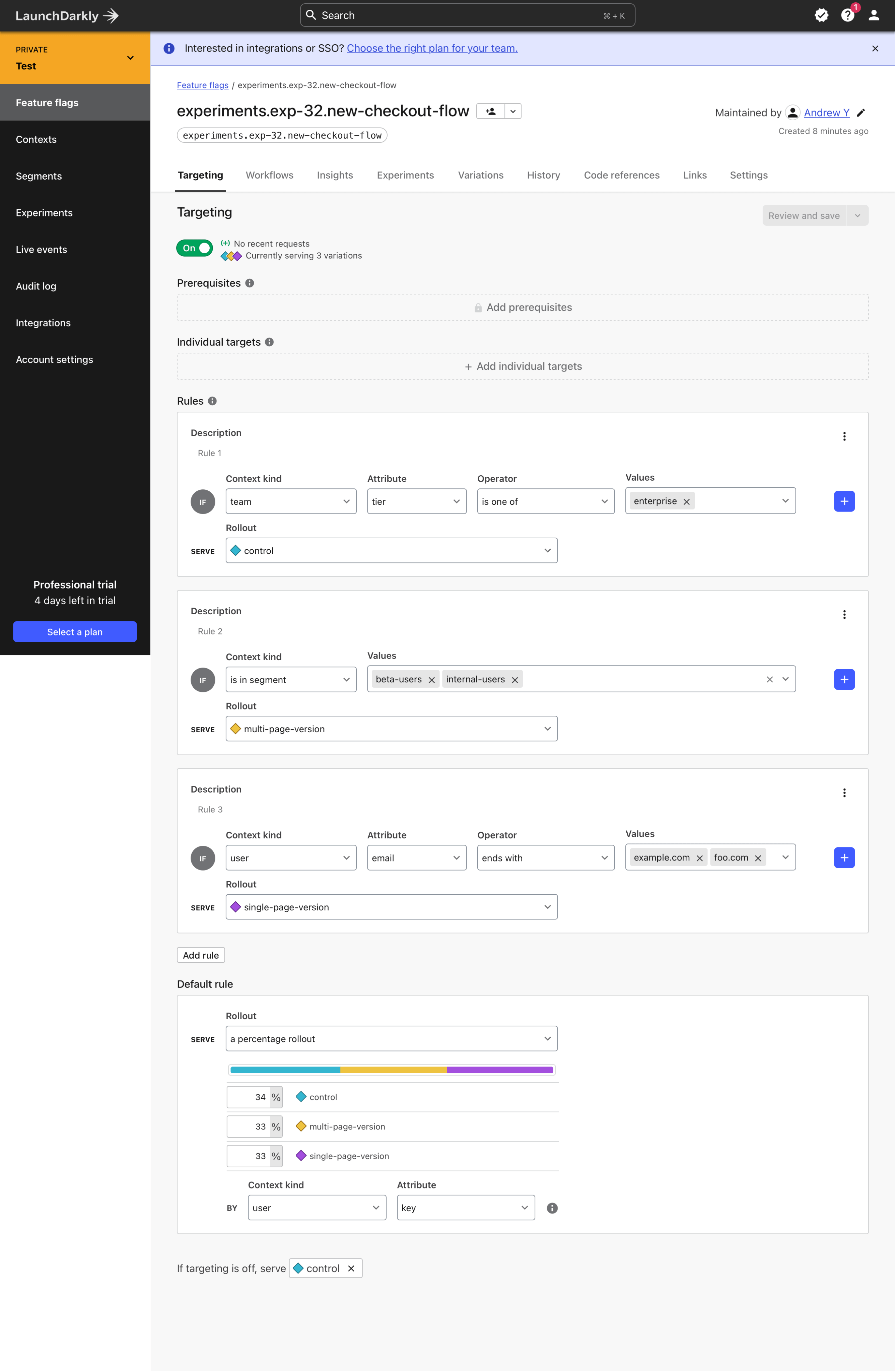
LaunchDarkly has all the features you'll need, but you're going to pay for it. The pricing is based on the number of users you have. Anecdotally this makes it quite challenging for larger orgs to rationalize the cost. A number of teams I've talked to end up sharing accounts, or building internal tools around the API in order to save money on seats, though of course this is a bad idea and negates the benefits of permissions and audit logging.
- Best for: Price Insensitive Enterprise.
- Test Case: 😀 Strong Pass.
- Price: Starts from $10 per user per month, however this is a low-ball. Many features / kickers force enterprise adoption. I've heard quotes in the range of "25 users for 30k a bucket" which is roughly $100/user/month.
- Features: All the basics plus: scheduling and workflows. AB testing & advanced permissions.
- Architecture: Enables the dev team to wrap code with feature flags and deploy it safely, ability to segment user base based on various attributes
- Notes: Flag editing view gets long, no read only overview to see flag rules at a glance.
ConfigCat
ConfigCat is a feature flagging service that also supports remote configuration.
ConfigCat did a good job supporting our test case. We can setup shared segments for the beta group and internal users, and a user attribute for the email.
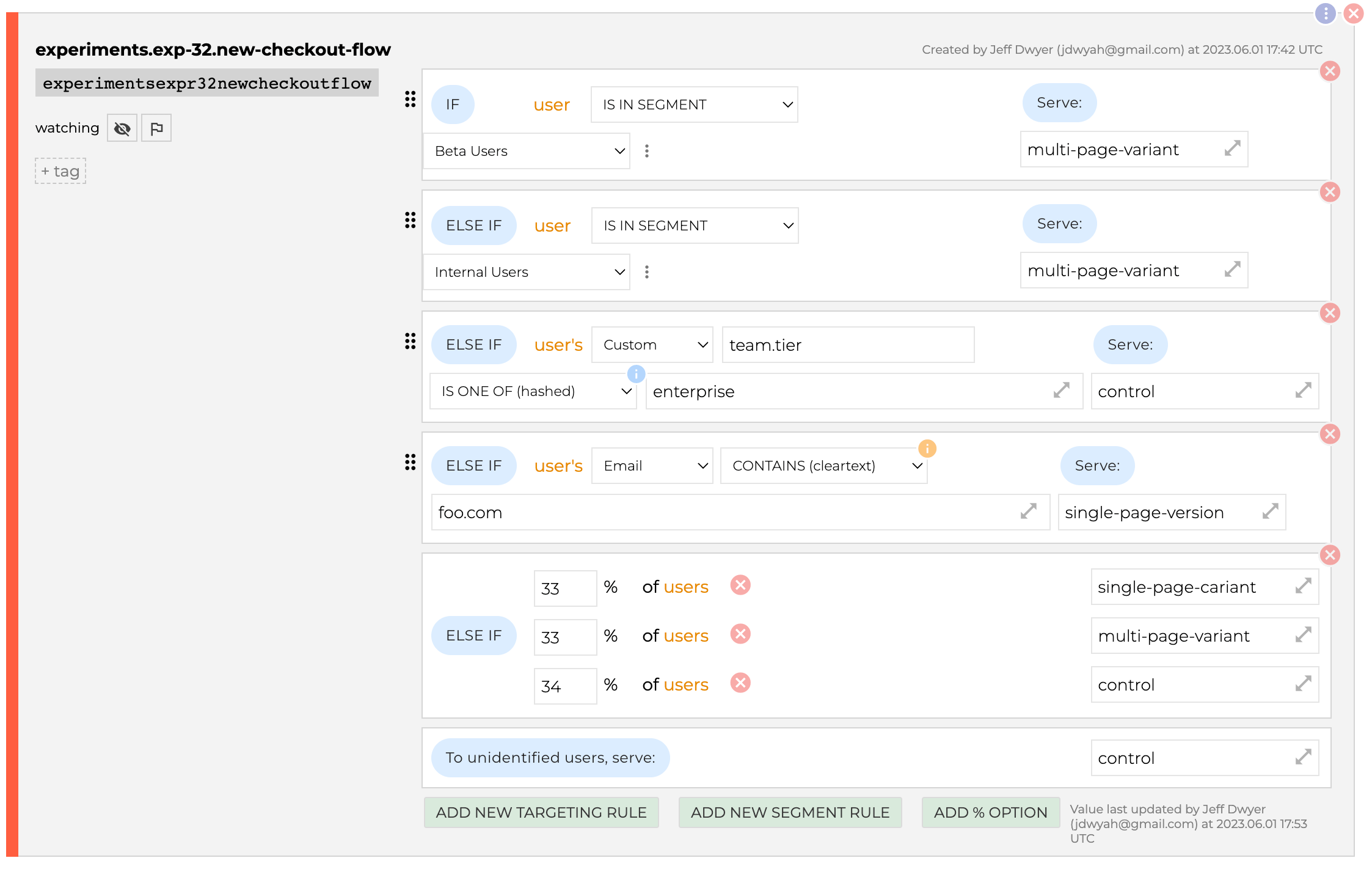 One important note is that it does not have a concept of "variants" each rule is returning a simple string. This means that you could mistype a variant from one rule to another, which is just something to be aware of.
One important note is that it does not have a concept of "variants" each rule is returning a simple string. This means that you could mistype a variant from one rule to another, which is just something to be aware of.
ConfigCat Takeaways
- Best for: Developer focussed configuration.
- Test Case: 😀 Strong Pass.
- Price: Free for up to 10 flags. Tiers at $99 and then $299 for unlimited flags and > 3 segments.
- Features: Shared segments, Webhooks, ZombieFlags report
- Architecture: Polling, server side evaluation.
- Notes:
- No concept of variants.
- I couldn’t do email
ends_with_one_of. I could do match one of or contains.
- Updates via polling, not real-time streaming.
Devcycle
Devcycle is a feature flagging service focussed on developers. Let's see how it fares on our test case.
Overall, Devcycle did well and I was able to setup our test case. The main knock was the lack of shared segments, meaning that I'll need to define the Beta group in multiple flags and risk them getting out of sync.
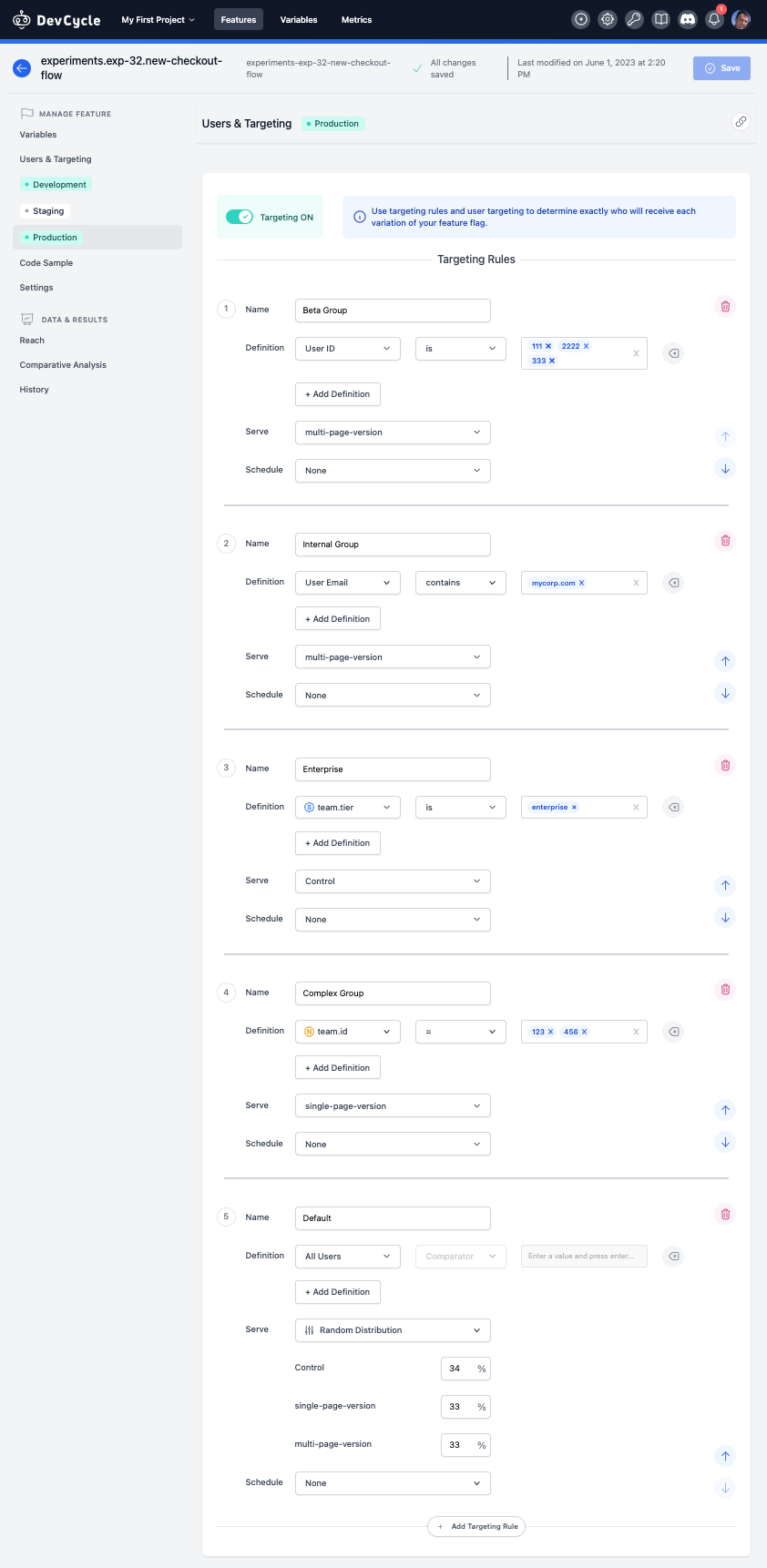 The resulting UI does end up very long making it a bit of a challenge to get an overview of the test.
The resulting UI does end up very long making it a bit of a challenge to get an overview of the test.
The UI was generally straightforward, however found it annoying to have to specify a name for each of my rules.
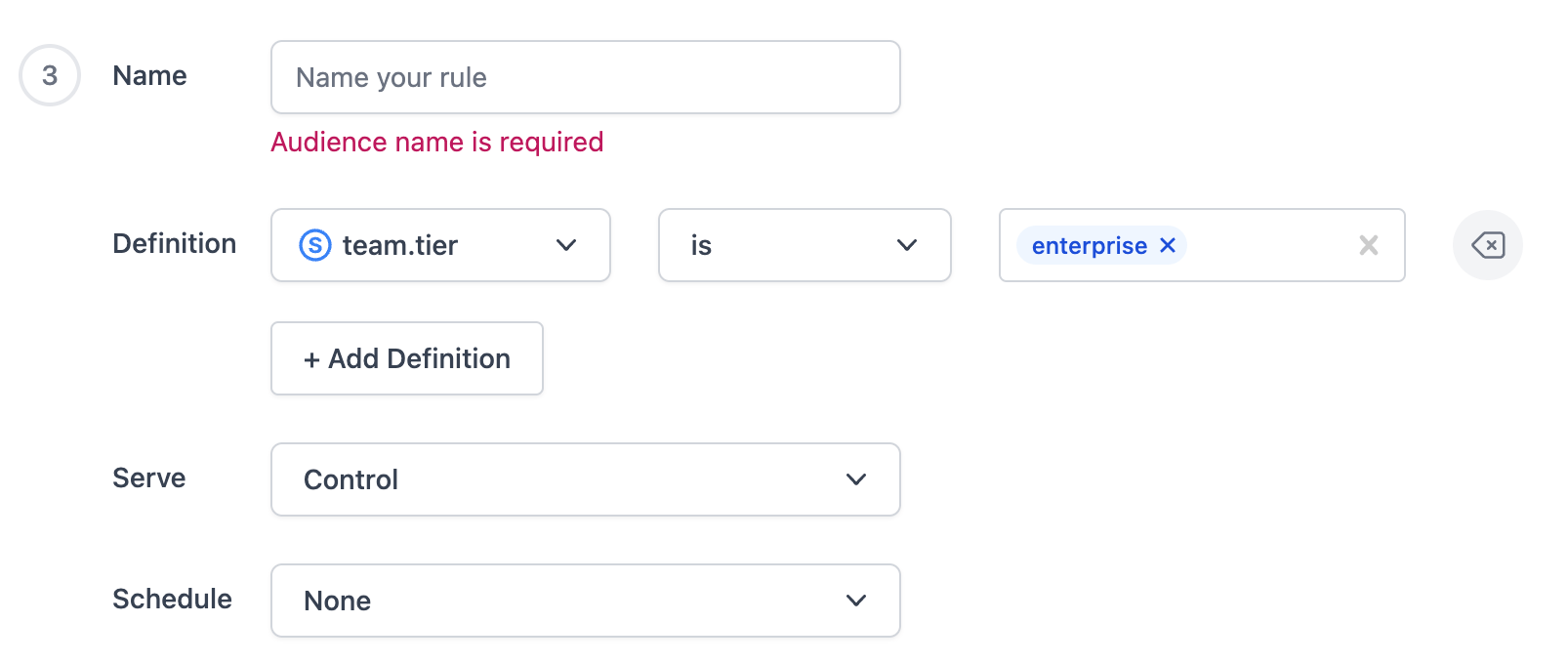
DevCycle Takeaways
- Best for: Developer focussed configuration.
- Test Case: 😐 Pass, but no shared segments.
- Price: Free for up to 1000 MAU. $500 for 50k MAU+. Pricing axis on client side MAU and Events.
- Features: AB Testing with Metrics
- Architecture: Streaming & Polling, server side evaluation.
- Notes:
- No shared segments
- Redundancy in UI meant it was hard to get an overview of our test.
- Offers typed context
Summary
That's a wrap. We looked at 7 different flag providers and how they handle a common test case. We gave "Strong pass" to 4 of the tools. 2 of the tools got a "Pass" because they lacked segments and 1 got a "Fail" for not supporting multi-variate flags.
| Competitor | Best For | Test | Cost | Pricing |
|---|
| Flipper Cloud | Rails Only. | 🙁 | 💰💰 | $20 / Seat Link |
| Prefab | Functionality for Less at any Scale | 😃 | 💰 | $1 / Connection. Usage based. Link |
| Unleash | Privacy / EU Compliance | 😐 | 💰💰 | $15 / seat Link |
| Flagsmith | Flexible deployments & On-Prem Deployments | 😃 | 💰💰 | $20 / seat Link |
| LaunchDarkly | Price Insensitive Enterprise | 😃 | 💰💰💰💰 | $17 / seat, $70+ / seat for all features Link |
| ConfigCat | Developer focussed configuration | 😃 | 💰 | $99 for > 10 flags. Usage based. Link |
| Devcycle | Developer focussed with Metrics | 😐 | 💰💰 | $25 for 1000 MAU. $500 for 50k MAU. Usage based. Link |