That image is adorable enough1 that I could leave it there and call it a day. But my coworkers insist I talk a little about the SDK.
The Go SDK gives you the Prefab goodness you've come to expect. It is perfect for scenarios where you need to make decisions at runtime based on feature flags or tune your app in production with live config. Whether you're rolling out a new feature gradually, running A/B tests, or managing different settings across environments, the Go SDK has you covered.
I've really enjoyed Go as a language. It has a simple syntax, it's fast, and it's easy to deploy. It feels like an excellent fit for a lot of the work we do at Prefab. We've been using it happily in our Slack Integration and our new Global Delivery service.
If you check out the Go SDK documentation, you'll see that it's straightforward to use. You can install it with go get github.com/prefab-cloud/prefab-cloud-go@latest, set up a client, and then use it to get feature flags and configs.
Let's take a look at the Prefab pricing page and go step through step how we modelled it using Stripe's new Usage Based Billing APIs.
Prefab sells things like Feature Flags and Dynamic Log Levels with awesome developer tooling. We charge money on two dimensions, both of which try to reflect the effort it takes us to support our customers. Those dimensions are:
Servers
We need to keep a live connection open for each of the servers side SDK that you use to connect. We charge $2 / server for this, but that goes down to $1 or $.80 at higher volume.
Requests
Front end clients make requests to get feature flag evaluations. We charge for these requests at the rate of $10 per 1.5M, with better pricing on the higher tiers.
To setup billing in Stripe, you need to decide what your products and prices are going to be. This sounds like it should be easy, but there are actually a lot of different ways to go about modeling things. Here's what we did.
In this diagram the green boxes represent the "product" and the blue represent prices.
Having a single "product" for "Servers" is clearly the right move, but what about the base tier pricing? You could probably model the 3 Free/Basic/Enterprise as a single "product" called "platform" with 3 different prices. Why not do that? Well the Stripe pricing table let's you use an HTML widget <stripe-pricing-table>. It was our intention to use this weidget, because the less code the better, right? When you go to setup that widget however, it was very much "add your product" as the primary choices. Since for us, the choice here is Basic/Pro/Enterprise, this lead us to have a Product for each.
note
The <stripe-pricing-table> lets you add more than one price for the same product, but this seems to be for allowing monthly / annual billing.
Originally, we were purely usage based, ie "just $1 / server" but we discovered customers wanted easier ways to estimate their bill. Ask a customer to estimate their bill and there's friction, but tell them it's "$99 for up to 100 server connections" and they can just say "oh great, we have fewer than that so the bill won't be more than $99/month". It's a touch irrational when you've got your engineer hat on, but it turns out that being kind to the actual people doing the software purchasing is a good idea for us.
In order to have tiers in combination with usage based overage we end up with pricing of the form "$99 for the first 100 and then $99 per 100 after that". The term of art for this is Graduated / Tier based pricing even though our tiers are the same price. We'll get into more details shortly.
When we go to create a subscription, we'll see that a subscription is basically just a payment method, associated with a set of prices. Each connection is called a SubscriptionItem.
Here's an ER diagram of the billing modeling, representing a customer subscribed to the Pro plan. You can see that the basic and enterprise prices are not connected to the user's subscription.
tip
I've named the prices Pro.Servers.0 I would highly recommend that you do something similar and add in a number to indicate the price version. These prices are pretty immutable once you get going and it's easy to make mistakes. A little bit of version control in your naming will prevent server-price-basic-v2-copy-use-this-one type fiascos.
The important take-away here is that in our world, there are really "tightly correlated prices". If you have the "pro" prices for your subscription, then you need to have the "pro.server" price for your Server product.
The main code that we're going to end up writing is the logic to ensure that these prices remain correlated as subscriptions change.
Here's the data model of Stripe's usage based billing, right from their documentation.
This is much better than the previous model, which we discussed earlier.
Our usage based tracking is really going to be very simple. For the prices basic.requests.0, pro.requests.0 etc, we just set them up to reference the same meter: billable_requests. This makes our code that records usage totally oblivious to what subscription the customer has, which is just what we want.
This is also really useful for trials / free tiers. We create a customer for each Prefab team when they signup and we can instantly start tracking usage for them against a Meter. Eventually our customer will add a subscription and at that point the usage can start making it onto an invoice. But it's nice to be able fully separate the concern of measuring and tracking usage from the more intricate dance of creating and adjusting subscriptions & prices.
Ok, so we've seen how we modelled our Products and Prices. We've started recording metered usage for our customers. How do we connect the two? How do we actually create a subscription and add the correct 3 prices as subscription items?
The promise of Stripe handling the entire pricing table was appealing to me. With our product information already in the system, I was able to quickly create a PricingTable object from my Stripe Product Catalog and then I just dropped the following into my billing page.
This rendered me a nice looking pricing table and clicking on the button took me to a nice checkout experienve, so at first I thought I was all done.
Problems:
A small thing, but I had to make a separate dark mode and light mode table which was... unfortunate.
It only worked for Creating a subscription. I couldn't use the same tool to let people upgrade / downgrade a subscription. This was bigger bummer. (You see I can only 'cancel' the subscription from the Customer Portal).
Because of #2, if I was going to let people switch from Basic to Pro without canceling Basic, I essentially felt the need to rewrite a pricing table. If I was going to do that anyway, then I wanted it to be consistent, so I did not end up using this pricing widget.
We don't actually have to add the servers and requests prices here, since the webhook would reconcile them for us. However the checkout page is better if it has all 3 prices at the time of customers adding a credit card.
defprocess_webhooks case data.dig("type") when'customer.subscription.created'||'customer.subscription.updated' process_subscription end end defprocess_new_subscription subscription = data.dig("data","object") team = Team.find_by_stripe_customer_id(subscription.dig("customer")) ensure_correct_subscription_items(team) end defensure_correct_subscription_items(team) subscription = team.get_subscription prices_to_add(subscription).eachdo|price_id| Stripe::SubscriptionItem.create({ subscription: subscription.id, price: price_id }) end subscription_items_to_remove(subscription).eachdo|item| Stripe::SubscriptionItem.delete(item.id,clear_usage:true) end end defprices_to_add(subscription) ## if subscription is Pro, return [pro.requests.0, pro.servers.0] end defprices_to_remove(subscription) ## if subscription is Pro, return anything that isn't "pro.*" end
Backing all of this, we did have to have a map of these "associated prices". When the "reconciler" runs it can use this mapping to find the request and server price ids for the given product price id.
This big file of the various Pricing IDs is not my favorite, but it works. I considered Stripe Terraform but it didn't have support for the new Meter object yet. I considered generating my prices in code and then saving the IDs out to a file. That might be a more elegant solution, but the quantity of these was below the threshold that was an obvious win for automation in my opinion.
The great thing about Stripes new support for Usage Based Billing and Meters is that the "usage" part has gotten very simple and is hardly something you need to think about anymore. Just decide your meters and record usage for the customer.
It still takes a decent amount of thinking for correctly model your products and prices, but now you can focus on these as their own problem. I hope taking a look at what we did at Prefab was helpful. Get in touch if you want to run your modeling past me while this is all still loaded in my brain.
Stripe just launched a major update to their support for Usage Based billing. It's a big improvement and has made Prefab's billing code a lot simpler. Let's look at the change and how that impacts the code you need to write.
This was a problem for a few reasons. How do we get our usage code the correct subscription item? The source of truth for a customer's subscription has to be Stripe, but if our code needs to understand the details, that means catching a lot of webhooks and trying to maintain a local picture of the subscription. Subscriptions can be complicated beast too. Free trials, upgrades, downgrades & cancellations. SubscriptionItems are tightly tied to a specific Product & Price. There's a lot of opportunity for race conditions or missed edge cases.
The second issue was that this usage record needed to be created during the current billing period. That means that if you want something on the bill for March, you need to write the usage record during March. Again, the edge cases abound. What about usage in the last minute of the hour in March? What about failure scenarios in your billing or aggregation code?
Prefab charges based on the number of requests to the Feature Flag evaluation endpoint. But I couldn't just tell Stripe that customer A did 1M API requests. I had to tell Stripe to put 1M API requests onto the specific pro tier pricing subscription item for a given customer.
So now it's all better. To put the usage onto the meter, all we need to know is the stripe_customer_id.
Now we create as many Prices as we need for the given Meter. At Prefab that means a Basic, Pro and Enterprise price. I went through a full break down of how we've modeled our pricing and usage in modeling usage based billing at Prefab. Our usage aggregation code is blissfully unaware of trial end dates, upgrades or cancellations.
note
The price itself can hold the more complex logic. On our Basic tier, there's no up-front cost for 1.5M requests (~= 5k feature flags MAU). After that it's $10 per 1.5M requests. So our price is a Usage Based, Per tier, Graduated pricing. The first tier is 1->15M for $0 and after that it's .00000666 / request.
At Prefab, we see a lot of Feature Flag evaluations. Far far too many to be writing the usage to Stripe for each evaluation. We aggregate the data a two different levels, once inside our backend code, with an in-memory aggregation. This outputs to BigQuery. We then do a second level of aggregation to rollup to hourly level data. We store this in Postgres where it's move convenient to query. Finally we have another job that pull from this table and writes the data to Stripe.
Ideally, usage that happens in March should land on the March bill. But it turns out that's easier said than done. For usage that happens in the last hour of the last day of March, just what exactly are the mechanics for getting that usage onto the March bill?
In the legacy system, all billing usage needed to be updated during the current billing period. See the note in the legacy documentation:
Reporting usage outside of the current billing period results in an error.
During the first few minutes of each billing period, you can report usage that occurred within the last few minutes of the previous period. If the invoice for the previous period isn’t finalized, we add that usage to it. Otherwise, we bill that usage in the current period. After the grace period, you can’t report usage from the previous billing period.
Don’t rely on the grace period for reporting usage outside of a billing period. It’s intended only to account for possible clock drift, and we don’t guarantee it.
There's a bunch of built-in delay in this pipeline while we wait for these aggregation steps so it was very possible for things to run past the end of the "clock drift". We could have adopted a more streaming / dataflow version of this, but that wouldn't really solve the problem. Pipelines can freeze / pause too. We want a billing system that can reliably put the right usage on the right bill even if there's more than 5 minutes of latency in the pipes.
The new system supports:
Recording usage before a Customer has created a subscription.
A full 1-hour grace period for usage recorded after invoice creation.
Cancelling events that have been sent to Stripe within the last 24 hours.
Backdated subscription creation to capture usage from before a subscription was created.
If you charge $100 per 15M requests with the first 15M requests free and the customer makes 16M requests, what should the bill be?
If you answered $6.66 that suggested you want it to be graduated.
If you answered $100 that suggests that you're thinking like enterprise software ;)
As engineers, the rate makes sense to us and usage based billing gives me some comfort with non-round numbers.
It turns out that software buyers are not necessarily rational however and a lot of people would prefer a bill that is $99, $99, $99 vs a bill that bounces all over the place like: $71, $92, $53.
We haven't exactly decided which way we'll go on this. But for now the limitation is actually a technical one so we are charging in the graduated manner. We would like the flexibility to be able to charge for a "bucket" of requests. What this requires is that we could set the pricing to have a transform_quantity option. In our case we would transform_quantity / 15_000_000 to get the number of buckets and then charge $99 per bucket. At the time of this writing this was not an option with tiered usage based billing at Stripe, but I'm assured that it's just around the corner.
Stripe's new Usage Based billing support has been a big upgrade for us. Our code has better separation of concerns. We have a much improved story around consistency and reliability even in the face of delays in our aggregation pipelines. We're really excited to see where Stripe takes this next, particularly when it comes to support for detailed breakdowns of our invoices.
tl;dr As of 1.6.0 prefab-cloud-ruby's dynamic logging now works by being an injectable filter for semantic_logger rather than a full logging library, ie SemanticLogger.add_appender(filter: Prefab.log_filter). This is awesome.
After we released our dynamic logging library for Ruby, I stepped back and tried to do an overview of the pros and cons of the major logging libraries in the Ruby ecosystem in Before You Lograge.
Kudos to the author for not putting their company's product at #1 when it is clearly a very solid #2. I had forgotten how good semantic logger is.
It's nice to feel people appreciated me being fair. But also... kinda stinks to be #2.
The fact of the matter was that they were right. Semantic Logger is awesome. It's been around for 12 years, it's had 62 contributors. It's a solid piece of code that can deal with whatever weirdness Rails throws at it and has had time to build custom appenders for everything from: Sentry to syslog, DataDog to Splunk.
At Prefab we really don't want to be in the business of building logging libraries. We want you to be able to turn on debug logging for a single customer in an instant, with our dynamic logging, but we don't really want to have an opinion on your aggregator, your formatting or how logging integrates with Rails.
In other languages, like Java or Python the standard logging libraries have a clear place to inject a custom filter and this was perfect for us. In Ruby however, the standard logging libraries didn't have any concept of a pluggable filter, so in our initial version we ended up rolling our own.
This worked quite well, but we were always going to be behind SemanticLogger when it came to a question of:
Supporting lots of different logging sinks/aggregators
# ElasticSearch example SemanticLogger.add_appender( appender::elasticsearch, url:"http://localhost:9200", index:"my-index", data_stream:true ) # LogStash example log_stash =LogStashLogger.new(type::tcp,host:"localhost",port:5229) SemanticLogger.add_appender(logger: log_stash)
SemanticLogger.tagged(user:"Jack",zip_code:12345)do # All log entries in this block will include the above named tags logger.debug("Hello World") end # 2024-04-01 D {user: Jack, zip_code: 12345} MyController -- Hello World
Standardizing the very odd output of Rails logging internals
See rails_semantic_logger for details, but we get really nice structured breakdowns of Rails' internal logging.
All of this is to say that as of 1.6.0 we're very happy that prefab-cloud-ruby works by leveraging semantic_logger and implementing dynamic log levels where they were meant to be, as a filter.
To get dynamic logging level for all of your code, you just need to:
# config/initializers/logging.rb SemanticLogger.sync!# Use synchronsous processing for targeting logging with current context SemanticLogger.default_level =:trace# Prefab will take over the filtering SemanticLogger.add_appender( io:$stdout,# Use whatever appender you like filter: Prefab.log_filter,# Insert our Prefab filter )
PR (#173) was a delightful +304/-1046, which reflects all of the work that we no longer had to do by being able to just rely on our new logging friend.
I've got a fun sleuthing mystery for you today. Follow along and see if you can figure out what the problem is before the end.
So we're spinning up a new application at Prefab. (We want to offer SAML to our customers. So we're building out a quick authentication app, with the idea that perhaps we also sell this as a service one day.)
This is a brand new Rails app, 3 weeks old. We deploy to kubernetes which is running in GKE autopilot.
So first things first, we pull out Lens and see we've got some OOM. Okay, that's annoying and a bit surprising. It's configured for 768Mi and that should be enough since we've got other rails apps doing more with less, so something is weird.
And when I say "running out of memory" I don't mean "slow memory leak". This this is getting killed very quickly. 1, 2 minutes and kaboom.
What's very odd though is that the service is actually up! The pod is getting killed constantly, but.. actually 1 pod of the 2 pod deployment is happy. What the heck??
Well, let's see if we're just under-provisioned / give it a bit more room to see what happens. Let's give it 3GB as overkill and see what happens.
Nope! That's a hungry hungry hippo, easily chewing through 3GB of memory.
Huh.. those are pretty pictures, but... I don't see any sign of a memory leak. Allocations, heap all look fine. If anything it's reporting way too small. It's saying there's only 26mb and it's not growing. huh.
Ok, well let's try some rack-mini-profiler, because I've had luck with that before. This let's us append ?pp=profile-memory to any URL and get output that includes:
and... basically same thing.
note
Allowing just anyone to ?pp=profile-memory on your production instance is a terrible idea, so this doesn't work out of the box. I enabled it with:
#application_controller.rb before_action do if Prefab.enabled?("rack.mini-profiler") Rack::MiniProfiler.authorize_request end end
and
#application.rb config.to_prepare do# https://github.com/MiniProfiler/rack-mini-profiler/issues/515 Rack::MiniProfiler.config.enable_advanced_debugging_tools = Prefab.get("rack.mini-profiler.enable_advanced_debugging_tools") end
Which let me turn this on as a targeted feature flag.
Either way, I'm not seeing anything suspicious here. The overall memory allocations are nothing like the 3GB monster that I'm seeing in the Datadog metrics.
At this point I'm pretty confused. Conventional wisdom on the Internet is that jemalloc is better, so I threw that at the wall.
RUN apt-get update && apt-get install -y libjemalloc2 ENV LD_PRELOAD=libjemalloc.so.2
That shouldn't fix a leak, but... maybe magic happens? Nope. No discernible change.
Feature Flags are great and you should use them. This was not a very fun day at the office, but all this sleuthing around would've been soooo much worse if there were any customers using this service. As is this just made a lot of noise and affected internal testing, but we could turn it off at anytime because it was flagged.
So we had a lot of alarms going off because something was unhappy in production, but there was no actual impact on customers. This is living the Feature Flag dream!
So use feature flags everyone. Use your internal tool or some other SaaS or ours, but USE THEM! Yay for feature flags.
If you guessed it's DHH's fault you win! (Please read this with the loving kindness I intend, I just had a chuckle that it was actually his commit that caused this issue.)
The answer is that a commit in a very recent Rails release triggered our app to behave weirdly when deployed.
Rails recently did a bunch of upgrades to the default puma configuration. This issue in particular was actually really interesting and an awesome look at a lot of smart people negotiating in public: https://github.com/rails/rails/issues/50450. The upshot is while Rails did a bunch of work on Puma and while better in most cases, one commit had some pathological behavior on shared hosting.
Rails / Puma is different then many other languages / frameworks in that it typically uses a combination of threads and workers. In other languages like Java you would run a single process and then parallelize with threads. In Ruby it's common to do process fork to gain parallelism with shared memory. Forking is when we get another copy of our process. It shares some memory because of copy on write, but in general it's a whole new process with its own memory overhead.
The key diagnostic step that blew the case wide open was the humble top command. James ran it on the happy pod and saw a handful of ruby processes. Then he tried it on the evil pod and saw... OMG SO MANY RUBY. Yep, 32! ruby processes all chugging away.
What happened? Physical Processors In A Virtual World
We're running GKE autopilot. This is a fully managed kubernetes that is very easy to set up and we quite like. We don't need to worry about anything expect our pods and how much cpu / memory we want them each to have.
This is fine, up until the point that a pods starts asking tough questions about the underlying hardware. Shared hosting means my pod may be on a 4CPU instance or a 64CPU instance. In our case, we have 2 pods guaranteed to run on different instances because of anti-affinity rules. In particular, one of the pods ended up on a e2-standard-4 and one is on a e2-highcpu-32. So one pod was running with 4 workers and one was trying to spawn 32 workers. That explains the 3GB of memory usage!! And this explains why we had one good pod and one evil pod.
I believe it also explains is why the Datadog profiling and ruby memory profiling tools didn't work as expected. Each worker of a ruby process is a FORK. It's a different pid, different process, no communication back to the mothership. So when we're running ObjectSpace and other things, we must just looking at our little slice of the universe, and each slice of the universe was fine. It was just a case of too many slices.
This also explains why this only affected our newest app. This change came into Rails recently in the 7.1.0.beta1 and this was our only app on Rails 7.1.
We did it! We removed Concurrent.physical_processor_count by hand and replaced it with our config system since that's how we roll. For us that looked like the following, but ENV vars or hardcode would fix too.
threads Prefab.get("rails.min.threads"), Prefab.get("rails.max.threads") if Prefab.get("rails.worker.count")>1 require"concurrent-ruby" workers Prefab.get("rails.worker.count") end
And it worked! Our hippos have been satiated.
My particular take-away from this was a reminder to my future self that forking makes diagnostic / observability tools behave quite differently from some of my expectations. That's a tricky one to keep in mind as I bounce between languages.
Prefab Founding Engineer. Three-time dad. Polyglot. I am a pleaser. He/him.
If you're just starting the LSP, you might wonder what language to build your Language Server (LS) with. This article will help you pick the right language. You can choose anything (seriously, I built a toy Language Server in Bash). There's no universally correct answer, but there’s a correct one for you.
Your audience is the most important consideration. If you're writing a language server for a new Python web framework (Language Servers aren't just for languages, people), then implementing the language server in Java might raise a few eyebrows.
The audience for a Python framework is less likely to contribute to a language server written in a language they're less familiar with. There's nothing wrong with Java (IMHO), but the biases associated with languages could hurt adoption.
If your language server is for a specific language or tooling tied to a specific language, you should probably use the same language to build the server.
If you're building your language server as a hobby, the first user is yourself. Optimize for your own enjoyment.
You’re less likely to have fun building if you pick a popular language with unfamiliar (or poor) ergonomics. If you're not having fun, you're less likely to get very far with the project, and your language server won't ever matter to anyone else anyway.
This doesn't mean you should limit yourself to languages you're already an expert in -- building a language server is a great way to learn how a new language handles
Unless you're building a language server to replace one that is demonstrably slow, you should probably avoid optimizing your decision for performance. Measure first before you start hand-coding assembly code.
You're a developer; I get it. You want to think performance matters. Suppose computationally intensive behaviors are required to calculate diagnostics/code actions/etc. In that case, you can always shell out to something tuned for performance and still keep the Language Server itself implemented at a higher level.
Don't worry about performance. It isn't important at first, and you have options later.
Many languages already have libraries that provide abstractions to help you write language servers. These can jump-start your development but aren't going to make or break your project.
You have all the building blocks you need if you can read and write over stdin/stdout and encode and decode JSON.
Learn more and build alongside me in my LSP From Scratch series.
You can build a language server without third-party libraries.
If the considerations above haven't helped you pick a clear winner, choose TypeScript (or, if you must, JavaScript).
The first-party libraries (e.g., vscode-languageserver-node) are in written TypeScript, and the community and ecosystem are excellent. A discussion on the vscode-languageserver-node project often leads to an update to the spec itself.
As a bonus, servers written in TypeScript (and JavaScript) can be bundled inside a VS Code extension and be available in the VS Code Marketplace as a single download. I've put up a Minimum Viable VS Code Language Server Extension repo where you can see how this all fits together.
It's common to use static site generators like Jekyll or Docusaurus for marketing or documentation websites. However, it's not always easy to run A/B tests when using these tools.
Prefab makes it simple. In this post we'll show how to setup an A/B test on a statically-generated Docusaurus website. We'll also show you how to send your experiment exposures to an analytics tool. We'll be using Posthog, but the process should be very similar for any analytics tool that has a JS client.
We recommend using the PrefabProvider component from our React library. In a normal React application, you would insert this component somewhere near the top level of your app. For a Docusuarus site, the easiest place to add it is in the Root component. That way Prefab will be available for experimentation on any page of your site.
Often A/B tests are bucketed based on users. To do that, we need some consistent way to identify the user, even if they're not logged in...which is usually the case for a static site. Luckily you can probably get an identifier from whatever analytics tool you have installed, or you can generate one yourself.
Your experiment is only going to be useful if you have data to analyze. Prefab is designed to work with whatever analysis tool you already have, so you don't have a competing source of truth. To do this we make it easy to forward exposure events to your tool of choice.
Typically you will have initialized your tracking library as part of the Docusaurus config. You can then provide an afterEvaluationCallback wrapper function to the Prefab client. This will be called after each use of isEnabled or get to record the flag evaluation and resulting value. In this example we're using the Posthog analytics platform.
<PrefabProvider ... afterEvaluationCallback={(key, value)=>{ window.posthog?.capture("Feature Flag Evaluation",{ key,// this is the feature flag name, e.g. "my-experiment" value,// this is the active flag variant, e.g. true, "control", etc. }); }} ... > {children} </PrefabProvider>
Here's an example chart from Posthog showing an experiment funnel going from experiment exposure to viewing any other page.
tip
Prefab also provides evaluation charts for each feature flag, which you can find under the Evaluations tab on the flag detail page. This telemetry is opt-in, so you need to pass collectEvaluationSummaries={true} to PrefabProvider if you want the data collected. While these are lossy and not a substite for analysis in your analytics tool of choice, they can be useful for troubleshooting experiment setup. Below is an example of an experiment with a 30/70 split.
Congrats, now you're ready to use Prefab from any Docusuarus JSX page or component. Import the usePrefab hook and use it to get a value for your experiment.
The Prefab client loads feature flag data via our CDN to ensure minimal impact on your page load speed. It also caches flag data after the initial load. You can read more about the Prefab client architecture in our docs.
There's a catch here, which is not specific to using Prefab. Since Docusaurus is a static site generator, it does not execute any server-side logic when pages are requested. There are more details in the Docusaurus static site generation docs.
This means that the page will first render the static version, which means no access to cookies or to the Prefab flags data. Once your React code runs client-side, it will render again with the correct feature flag values from Prefab.
So in the example above, the page will initially load without your experiment content. Then it will pop-in on the re-render. You'll have to make a judgement call on whether this negatively impacts the user experience, depending on where the experiment is on the page and how it affects the layout of other page elements.
The alternative is to render a loading state on the initial render, then display the actual content once the Prefab client has loaded.
constMyComponent()=>{ const{get, loading}=usePrefab(); if(loading){ return<MySpinnerComponent/> } switch(get("my-experiment")){ case"experiment-on": return(<div>Render the experiment UI...</div>); case"control": default: return(<div>Render the control UI...</div>); } }
You can read a more in-depth discussion of handling loading states in the Prefab React client docs.
Configuring the Experiment in the Prefab Dashboard
For a simple experiment with only a control and an experiment treatment, you'll want to create a boolean feature flag. The important part for making it an experiment is defining a rollout rule for targeting. Notice that we are setting user.key as the "sticky property". This means that Prefab will use the unique identifier we passed in for segmenting users into the two experiment variants.
Prefab Founding Engineer. Three-time dad. Polyglot. I am a pleaser. He/him.
So you've got a misbehaving function in your Node app, and you need to debug it. How can you get more logging? It would be great if you could add log lines to your function, but only output them when you need them so you don't create a bunch of noise & expense. You can do this with Prefab dynamic logging for Node.
Here's a really basic skeleton of an Express app. It's has a simple route that takes a user id from the url and returns some data from the database. Let's pretend it's misbehaving and we need to debug it.
We've added two console.log statements, but this probably isn't shippable as is because, at high throughput, we're going to print out way too much logging.
app.get("/users/:id",(req, res)=>{ const userId = req.params.id; var sql ="SELECT * FROM users WHERE id = $1"; console.log(`running the following SQL ${sql}`,{userId: userId }); db.run(sql,[userId],(err, rows)=>{ if(err){ // ... } console.log("query returned",{rows: rows }); res.send(`200 Okey-dokey`); }); });
The first thing we're going to do is add Prefab. We'll use the standard NodeJS server side client. This gives us an SSE connection to Prefab's API out-of-the-box so we'll get instant updates when we change our log levels.
const{Prefab}=require("@prefab-cloud/prefab-cloud-node"); const prefab =newPrefab({ apiKey: process.env.PREFAB_API_KEY, defaultLogLevel:"warn", }); // ... later in our file await prefab.init();
Rather than use a console.log we will create a Prefab logger with the name express.example.app.users-path and the default level of warn so we don't get too much output.
We can replace our console.log with some logger.debug and logger.info and now it's safe to deploy. They won't emit logs until we turn them on.
const logger = prefab.logger("express.example.app.users-path","warn"); // simple info logging logger.info(`getting results for ${userId}`); var sql ="SELECT * FROM table WHERE user_id = $1"; // more detailed debug logging logger.debug(`running the following SQL ${sql} for ${userId}`); db.run(sql,[userId],function(err, rows){ logger.debug("query returned",{rows: rows }); res.send(`200 Okey-dokey`); });
Listen for changes and Turn On Debugging in the UI
We can now toggle logging in the Prefab UI! Just choose express.example.app.users-path, change it to debug and a minute later you'll see the debug output in your logs.
To add per user targeting, we need to set some context for Prefab so it can evaluate the rules. We should move the logger creation inside this context so that the logger knows about the user id.
// take the context from our url /users/123 and give it to prefab as context const prefabContext ={user:{key: userId }}; // wrap our code in this context prefab.inContext(prefabContext,(prefab)=>{ const logger = prefab.logger("express.example.app.users-path","warn"); logger.info(`getting results for ${userId}`); var sql ="SELECT * FROM table WHERE user_id = $1"; // more detailed debug logging logger.debug(`running the following SQL ${sql} for ${userId}`); db.run(sql,[userId],function(err, rows){ logger.debug("query returned",{rows: rows }); return res.send(`200 Okey-dokey`); }); });
We can now create the rules in the Prefab UI for just 1 hour and just user 1234. This will let us see the debug output for just that user and automatically stop debug logging after the hour is up.
If we load the pages /users/1000, /users/1001 and /users/1234 we'll see the following output in our logs. We have INFO level logging for the first two, but DEBUG level logging for the last one because it matches our user.key rule.
INFO express.example.app.users-path: getting results for 1000 INFO express.example.app.users-path: getting results for 1001 INFO express.example.app.users-path: getting results for 1234 DEBUG express.example.app.users-path: running the following SQL SELECT * FROM table WHERE user_id = $1 for 1234 DEBUG express.example.app.users-path: query returned { rows: [ { id: 1, user_id: 1234, account: active, balance: 340 } ] }
Full Code Example
const express =require("express"); const{Prefab}=require("@prefab-cloud/prefab-cloud-node"); const prefab =newPrefab({ apiKey: process.env.PREFAB_API_KEY, defaultLogLevel:"warn", }); const app =express(); const port =3000; // Mock database for the purposes of this example const db ={ run:(sql, params, callback)=>{ callback(null,[]); }, }; constmain=async()=>{ app.get("/users/:id",(req, res)=>{ const userId = req.params.id; // take the context from our url /users/123 and give it to prefab as context const prefabContext ={user:{key: userId }}; // wrap our code in this context prefab.inContext(prefabContext,(prefab)=>{ const logger = prefab.logger("express.example.app.users-path","warn"); logger.info(`getting results for ${userId}`); var sql ="SELECT * FROM table WHERE user_id = $1"; // more detailed debug logging logger.debug(`running the following SQL ${sql} for ${userId}`); db.run(sql,[userId],function(err, rows){ logger.debug("query returned",{rows: rows }); return res.send(`200 Okey-dokey`); }); }); }); await prefab.init(); app.listen(port,()=>{ console.log(`Example app listening on port ${port}`); }); }; main();
To learn more about Prefab dynamic logging, check out the dynamic logging or check out the other things you can do with Prefab in Node like feature flags.
So you've got a misbehaving Netlify function and you need to debug it. How can you get more logging? It would be great if we could add log lines to our function, but only output them when we need them so we don't create a bunch of noise & expense. We can do this with Prefab dynamic logging for Netlify.
In this post, we'll add dynamic logging to our Netlify function that will let us turn on debug logging for:
Here's a really basic skeleton of a Netlify function. It's a simple function that takes a user id from the url and returns some data from the database. Let's pretend it's misbehaving and we need to debug it.
We've added two console.log statements, but this probably isn't shippable as is because, at high throughput, we're going to print out way too much logging.
exportdefaultasync(req, context)=>{ const{userId}= context.params; var sql ="SELECT * FROM table WHERE user_id = $1"; console.log(`running the following SQL ${sql}`,{userId: userId}); db.run(sql,[userId],function(err, rows){ console.log("query returned",{rows: rows}); returnnewResponse("200 Okey-dokey"); }); }; exportconst config ={ path:"/users/:userId" };
The first thing we're going to do is add Prefab. We'll use the standard NodeJS server-side client, but we'll turn off the background processes. Since we're running on a lambda, we don't want any background processes in our function.
import{Prefab}from"@prefab-cloud/prefab-cloud-node"; var prefab =newPrefab({ apiKey: process.env.PREFAB_API_KEY, enableSSE:false,// we don't want any background process in our function enablePolling:false,// we'll handle updates ourselves defaultLogLevel:"warn", collectLoggerCounts:false,// turn off background telemetry contextUploadMode:"none",// turn off background telemetry collectEvaluationSummaries:false,// turn off background telemetry }); await prefab.init();
Rather than use a console.log, we will create a Prefab logger with the name netlify.functions.hello and the default level of warn so we don't get too much output.
We can replace our console.log with some logger.debug and logger.info, and now it's safe to deploy. They won't emit logs until we turn them on.
const logger = prefab.logger("netlify.functions.hello","warn"); // simple info logging logger.info(`getting results for ${userId}`); var sql ="SELECT * FROM table WHERE user_id = $1"; // more detailed debug logging logger.debug(`running the following SQL ${sql} for ${userId}`); db.run(sql,[userId],function(err, rows){ logger.debug("query returned",{rows: rows}); returnnewResponse("200 Okey-dokey"); });
This logging will not show up in your Netlify logs yet, because the logger is warn but the logging here is info and debug. That means it's safe to go ahead and deploy.
Listen for changes and Turn On Debugging in the UI
Since we turned off the background polling, we'll want to update prefab in line. We can do this by calling the updateIfStalerThan with our desired polling frequency. This is a quick check to a CDN, taking around 40ms (once every minute).
prefab.updateIfStalerThan(60*1000);// check for new updates every minute
We can now toggle logging in the Prefab UI! Just choose the function, change it to debug, and a minute later, you'll see the debug output in your logs.
This is pretty cool and you can stop here if this solves your needs. With this pattern you'll be able to instantly turn logging on and off for any function in your app.
Now we'll go deeper and add per user targeting. This will let us laser focus in on a particular problem.
To add per user targeting, we need to tell Prefab who the current user is. We do this by setting some context for Prefab so it can evaluate the rules. We should also move the logger creation inside this context so that the logger has this context available to it.
// take the context from our url /users/123 and give it to prefab as context const{userId}= context.params; const prefabContext ={user:{key: userId}}; // wrap our code in this context prefab.inContext(prefabContext,(prefab)=>{ // logger goes inside the context block const logger = prefab.logger("netlify.functions.hello","warn"); logger.info(`getting results for ${userId}`); var sql ="SELECT * FROM table WHERE user_id = $1"; logger.debug(`running the following SQL ${sql} for ${userId}`); db.run(sql,[userId],function(err, rows){ logger.debug("query returned",{rows: rows}); returnnewResponse("200 Okey-dokey"); }); });
We can now create the rules in the Prefab UI for just 1 hour and just user 1234. This will let us see the debug output for just that user and automatically stop debug logging after the hour is up.
If we load the pages /users/1000, /users/1001, and /users/1234, we'll see the following output in our logs. We have INFO level logging for the first two, but DEBUG level logging for the last one because it matches our user.key rule.
INFO netlify.functions.hello: getting results for 1000 INFO netlify.functions.hello: getting results for 1001 INFO netlify.functions.hello: getting results for 1234 DEBUG netlify.functions.hello: running the following SQL SELECT * FROM table WHERE user_id = $1 for 1234 DEBUG netlify.functions.hello: query returned { rows: [ { id: 1, user_id: 1234, account: active, balance: 340 } ] }
Full Code Example
import{Prefab}from"@prefab-cloud/prefab-cloud-node"; var prefab =newPrefab({ apiKey: process.env.PREFAB_API_KEY, enableSSE:false,// we don't want any background process in our function enablePolling:false,// we don't want any background process in our function defaultLogLevel:"warn", collectLoggerCounts:false,// we don't want any background process in our function contextUploadMode:"none",// we don't want any background process in our function collectEvaluationSummaries:false,// we don't want any background process in our function }); exportdefaultasync(req, context)=>{ prefab.updateIfStalerThanSec(60*1000);// check for new updates every minute // take the context from our url /users/123 and give it to prefab as context const{userId}= context.params; const prefabContext ={user:{key: userId}}; prefab.inContext(prefabContext,(prefab)=>{ const logger = prefab.logger("netlify.functions.hello","warn"); logger.info(`getting results for ${userId}`); var sql ="SELECT * FROM table WHERE user_id = $1"; logger.debug(`running the following SQL ${sql} for ${userId}`); db.run(sql,[userId],function(err, rows){ logger.debug("query returned",{rows: rows}); returnnewResponse("200 Okey-dokey"); }); }); }; exportconst config ={ path:"/users/:userId" };
To learn more about Prefab dynamic logging, check out the dynamic logging or check out the other things you can do with Prefab in Netlify like feature flags.
We set this up to target a particular user, but you can easily target anything else you provide in the context. Team ID, transaction ID, device ID, device type are all common examples.
How should we integrate feature flags into Netlify functions? We'll explore why it's a bit tricky with lambdas, and I'll guide you through the best approaches to make it work efficiently.
Lambdas, like those in Netlify functions, are transient and don't run indefinitely. They're frozen after execution. This behavior poses a unique challenge for feature flags, which need to be swift and efficient and typically achieve this by using a background process to update the flag definitions.
Server-Side Flags: Here, your server connects to the flag server, downloads the necessary data, and performs local flag evaluations. This setup ensures no network calls during flag evaluations. Plus, we can manage telemetry asynchronously to avoid slowing down requests.
Client-Side Flags: Common in web browsers, this approach involves making a network call to fetch flag values. For example, sending user data to an evaluation endpoint on page load, which returns the flag states. These endpoints need to be optimized for low latency, because they get called on every request.
Netlify functions are neither purely server-side nor client-side. They can't run background processes traditionally, but they are more persistent than a web browser so it would be nice to avoid network calls on every request. So, what's the best approach?
Feature Flags in Netlify: The Browser-Like Approach
A practical solution is to treat Netlify functions similar to a browser. Prefab's Javascript client, for instance, caches flag evaluations per user in a CDN. Here's a sample code snippet for this approach:
In my testing from a Netlify function I see results around a 50ms latency initially and around then 10ms for each subsequent request for the same context. That may be too slow for some applications, but it's a good starting point and very easy to set up.
The nice thing about this solution is that you're going to get instant updates when you change a flag. The next request will have up to date data.
Alternatively, you can implement a server-side strategy using the Prefab NodeJS client.
The key will be configuring our client to disable background updates and background telemetry, then performing an update on our own timeline.
Here's a sample code snippet for this approach:
import{Prefab}from"@prefab-cloud/prefab-cloud-node"; var prefab =newPrefab({ apiKey: process.env.PREFAB_API_KEY, enableSSE:false,// we don't want any background process in our function enablePolling:false,// we'll handle updates ourselves collectLoggerCounts:false,// turn off background telemetry contextUploadMode:"none",// turn off background telemetry collectEvaluationSummaries:false,// turn off background telemetry }); // initialize once on cold start await prefab.init(); exportdefaultasync(req, context)=>{ const{ userId }= context.params; const prefabContext ={user:{key: context.userId}}; return prefab.inContext(prefabContext,(prefab)=>{ if(prefab.get("my-flag")){ // Your code here will } // ever 60 seconds, check for updates in-process updateIfStalerThan(60*1000); returnnewResponse("ok"); }); }; exportconst config ={path:"/users/:userId"};
With this approach, most of our requests will be fast, but we'll have a periodic update that will take a bit longer. This is about 50ms in my testing from a Netlify function. We're entirely in control of the frequency here, so it's a judgment call on how real-time you want your feature flag updates. You could even disable the updates altogether if tail latency is of utmost concern and you didn't mind redeploying to update your flags.
The best way to solve this problem would be to use a Lambda Extension which could run a sidecar process to update the flags, then serve the flag data over localhost to your function. Unfortunately, Netlify doesn't support Lambda Extensions yet, but this is an exciting avenue to explore for other serverless platforms.
Deciding between a browser-like or server-side approach depends on your specific use case in Netlify functions. Both methods have their merits. The browser-like method offers simplicity and instant updates to feature flags, whereas the server-side approach gives a much better average response time at the cost of some tail latency and a configurable delay seeing flag changes. Choose what fits best for your application's architecture and performance requirements. Happy coding!
We build configuration tooling here at Prefab, so it was a little embarrassing that our own local development configuration was a mess. We fixed it, we feel a lot better about it and we think you might dig it.
We used our own dynamic configuration for much of our config and that worked well, but when we needed environment variables everything started to fall apart. The pain points were:
Environment variables sound nice: "I'll just have my app be configurable from the outside". But in practice it can get messy. What are the default values? Do I need to specify defaults for everything? How do I share those defaults. When do I have fallback values and when do I blow up?
Beyond defaults, where do I put the environment specific overrides? Are these all in my devops CD pipeline? That's kinda a pain. Where are the production overrides? Could be anywhere! We had them in each of:
Because we have multiple services, we also had some of the defaults in ruby .env.example also showing up in our Java app in a src/main/resources/application-development.yml.
As if all of ^ wasn't enough of a mess. Secrets had to have an entirely different flow. We were good about not committing anything to source control, but it was a pain to get the secrets to the right place and easy to forget how to do it.
We were surviving, but it wasn't fun and the understanding / context fell out of our heads quickly meaning that whenever we needed to change something we had to reboot how things worked into our working memory and it took longer than it needed to. For a longer rant on environment variables, check out 9 Things I Hate About Environment Variables.
A single place to look to see all of our of my configuration
Developers have a single API key to manage, no local env var mysteries
Defaults that are easy to override for local dev, but weren't footguns leading to Works On My Machine issues
Easy to share configuration between projects
Interoperability with our Terraform / IaaS / Kubernetes variables
A system that supports secrets as well as configuration
Telemetry on what values are actually being used in production for our IaaS / Terraform provided values
We had a ton of the infrastructure in place to support this from our dynamic configuration work, but when it came to environment variables we were still in the stone age.
Our dream looked like this. With just a single api key and callsite, like:
#.env # One API Key per developer PREFAB_API_KEY=123-Development-P456-E2-SDK-c12c561b-22c3-4a52-9c38-a8f24355c102 #database.yaml default:&default database: <%= Prefab.get("postgres.db.name") %>
We wanted to be able to see all of my configuration in one place in:
The UI
The CLI
My Editor
The Prefab Config UI for a config using normal strings as well as provided strings.
It's clear what the value is in every environment and I can see which environments are getting the value from a Terraform provided env var.
The Prefab CLI running a prefab info call.
code (main) $ prefab info ? Which item would you like to see? postgres.db.name - Default: unused - Development: forcerankit_dev - Production: POSTGRES_DB_NAME via ENV - Staging: POSTGRES_DB_NAME via ENV - Test: forcerankit_test Evaluations over the last 24 hours: Production: 4 - 100% - forcerankit Staging: 1 - 100% - forcerankit
And even a hover in my editor using the VSCode extension.
Datafile support allows the Prefab client to start up using a single local file instead of reaching out to the Prefab API. This is useful for CI environments where you may want perfect reproducibility and no external network calls. You can generate a datafile for your local environment and then commit it to source control. This allows you to have a single source of truth for your configuration and secrets.
In our goal of having a "Single Source of Truth" for our configuration, the original system of default files like .prefab.default.config.yaml ended up being more of a hindrance than a help. There's a big difference between a UI that is all-knowing and a system that has partial knowledge that could be overridden by other files, re-introducing complexity into the system.
Making the API all-knowing is lovely, but if everything is in the API, what do we do for CI / Testing?
Our solution is to have 2 modes:
Live mode.
Datafile mode. Offline, load a single datafile.
The datafiles are easy to generate. You simply run prefab download --env test and it will download a datafile for the test environment. You can then commit that datafile to source control and use it in CI.
In CI environments you can then run PREFAB_DATAFILE=prefab.test.123.config.json and it will use that datafile instead of reaching out to the API.
The last big piece of this work was supporting secrets. If we were going to clean this all up once and for all, it just didn't work to still be on our own for secrets. I'll cover that in a future blog post, but if you're interested in our Secrets Management Beta please let us know. It's a zero-trust, CLI based solution that we think hits the nail on the head of being dead simple and easy to use.
We're really happy with how this turned out. Everything just feels... right. Configuration is important. Configuration goes in one place. It sounds like that should be easy, but from my experience up until now it's not the world many of us have been living in.
If you've been living in a monolith world deploying to heroku, you've long been enjoying the simple pleasure of heroku config:set GITHUB_USERNAME=joesmith. But if you have more than one application, apps in different languages, or weren't deploying to something simple like heroku, the story has been much worse.
What we've built has been a big improvement for us and we think it will be for you too. We're going to be rolling this out to all of our SDKs over the next few weeks. We'd love to hear what you think.
We're thrilled to introduce our new Editor Tools for React developers!
As React developers, we cherish our time in the editor. However, dealing with Feature Flags typically meant stepping out of that space. We pondered, "What if we could manage everything directly from the editor?" The result is something we're really proud of.
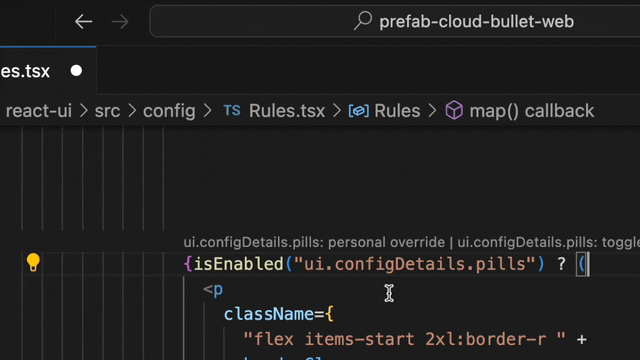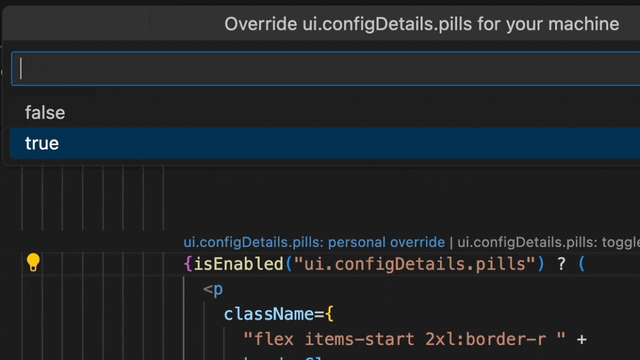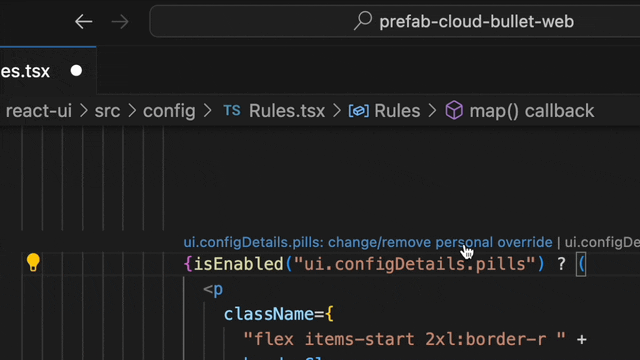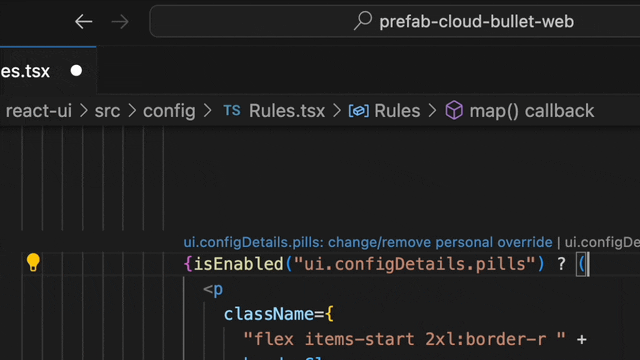
First off, we've integrated an autocomplete feature for feature flags. A wrongly typed feature flag can be a nuisance, especially since they default to false, leading to tricky debugging. Let your editor assist you. Enjoy autocomplete for flag and configuration names, and the ability to auto-create simple flags if they don't exist yet.
Implementing a feature flag is often straightforward. The real challenge is monitoring its status. Is it active? Can it be removed? What's its production value?
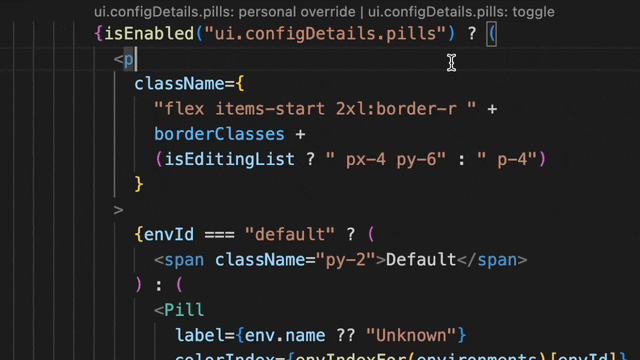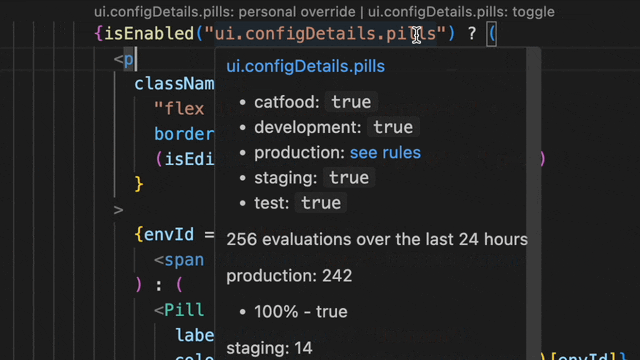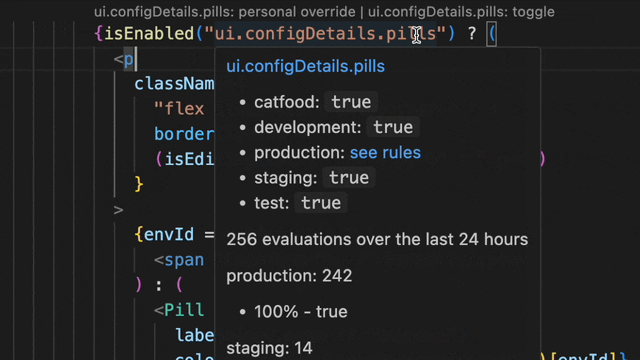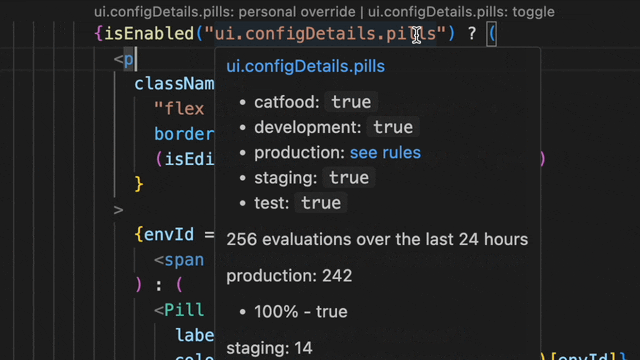
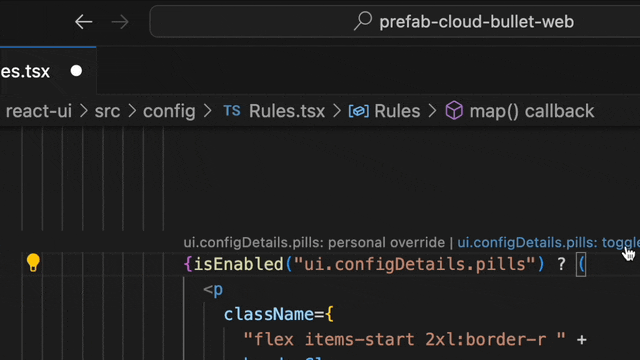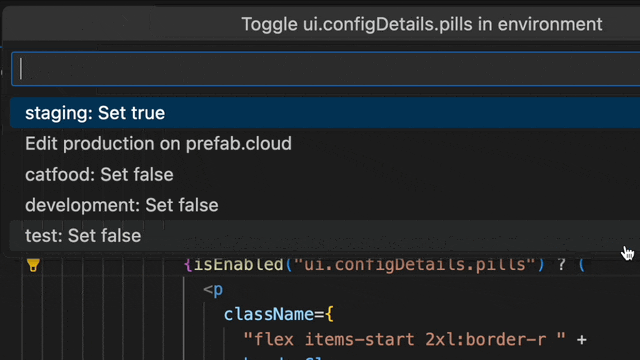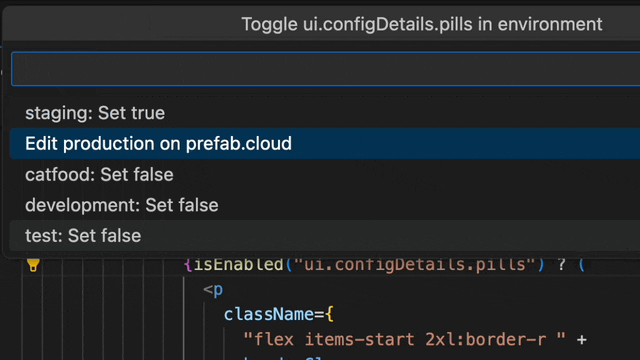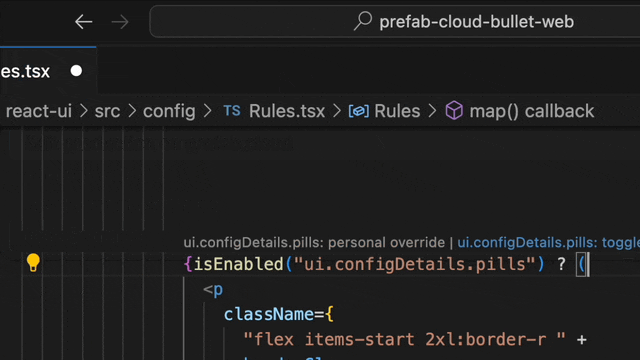
We envisioned how amazing it would be to integrate evaluation data directly into the editor. The result is indeed amazing! Now, you can get all the answers with a simple hover, without ever leaving your editor.
This lets you see if a flag is set to true in your staging or demo environment, or doing a percentage rollout in production.
Ever accidentally committed if true || flags.enabled?("myflag")? I've done it. It happens when I want to see a flag's effect but don't want to change it globally. So, I temporarily tweak it to true and then sometimes forget to revert it.
Wouldn't it be better to simply click on the flag and set it to true just for your local environment? This personal overrides feature, linked to your developer account, lets you do just that. Test your feature without disrupting others, all within your coding flow.
We're absolutely digging these tools internally and we're excited to expand upon them. We think the idea of being able to detect zombie or stale flags right in our editor would be very useful. We feel like we've taken a big step forward with the inline evaluation data on hover, but we're excited to keep pushing forward. We'd love to hear some of your ideas for how we can make these tools even better.