9 Things I Hate About Environment Variables

In the world of software development, environment variables are how we configure our applications. The Twelve-Factor app methodology made this canonical and was a significant improvement over the terrible things we'd done before. However, I think we can do better.
Looking at the big picture, we've essentially created a system of global, untyped variables with no declarations and no defaults – a scenario that would be unacceptable in regular code. Yet, here we are, using this approach for one of the most critical aspects of our applications.
Specific Challenges with Environment Variables
1. Environment Variable Whack-a-Mole
How often have you cloned an app only to be greeted with a slew of errors due to missing environment variables? Start the app, it explodes, hunt down the value for the env var, start the app, explode on another env var, etc. I asked a friend how big a problem this was on a scale of 1-10. I think he spoke for us all when he said: "Mostly a 1 or 2. Yesterday, it was an 11."
- Examples:
Api.get(key: ENV["THE_KEY"])will lead us to frustrating mysterious 401 errors when it isn't definedApi.get(key: ENV.fetch("THE_KEY"))will raise the error, but now we're mole-whacking.
- Doesn't Dotenv Fix It?: Sometimes. Dotenv has been a huge improvement but over time each developers local
.envstarts straying from the common.env.exampleand we get a lot of "it works on my machine" issues. Oh... and it's got nothing for secrets.
2. Scattered Defaults
Env vars are big global variables, and there isn't even a clear answer to where we put the values. Most codebases end up with a mix of defaults in the ENV invocation, some in .env files or maybe a .env.production file. Possibly a config/staging.yaml. Maybe something from our continuous deployment. Some things in a kubernetes configmap. It's a mess.
- Examples:
.env.productionusing dotenv for deployed envs.config/default.yamlorconfig/production.yamlYAML configs.config.x.swarm_count = ENV.fetch('SWARM_COUNT', 3)in-line defaults.config.x.configure_sys = !Rails.env.test?this looks like a config value but isn't actually updateable.
- Issue: Defaults are inconsistently spread throughout the codebase, creating a chaotic and confusing setup.
3. No Types & Unsafe Interpolation
Speaking of chaotic mess, how much fun is it debugging an issue when your env var is a string but you're expecting a boolean? Or when you're expecting an array delimited on comma, but somebody left a space in it, and the env var isn't quoted someplace. Good times.
- Examples:
config.x.use_seeds = ENV.fetch('USE_SEEDS', 'false') == 'true'(Potential boolean misinterpretation)config.x.cors_origins = ENV.fetch('CORS_ORIGINS', '').split(',')(Complications with array parsing)config.x.timeout_millis = ENV.fetch('TIMEOUT', '1') * 1000(Potential for unit mismatches abound)
- Issue: The lack of inherent type safety necessitates extra coding for handling data types, increasing the risk of errors.
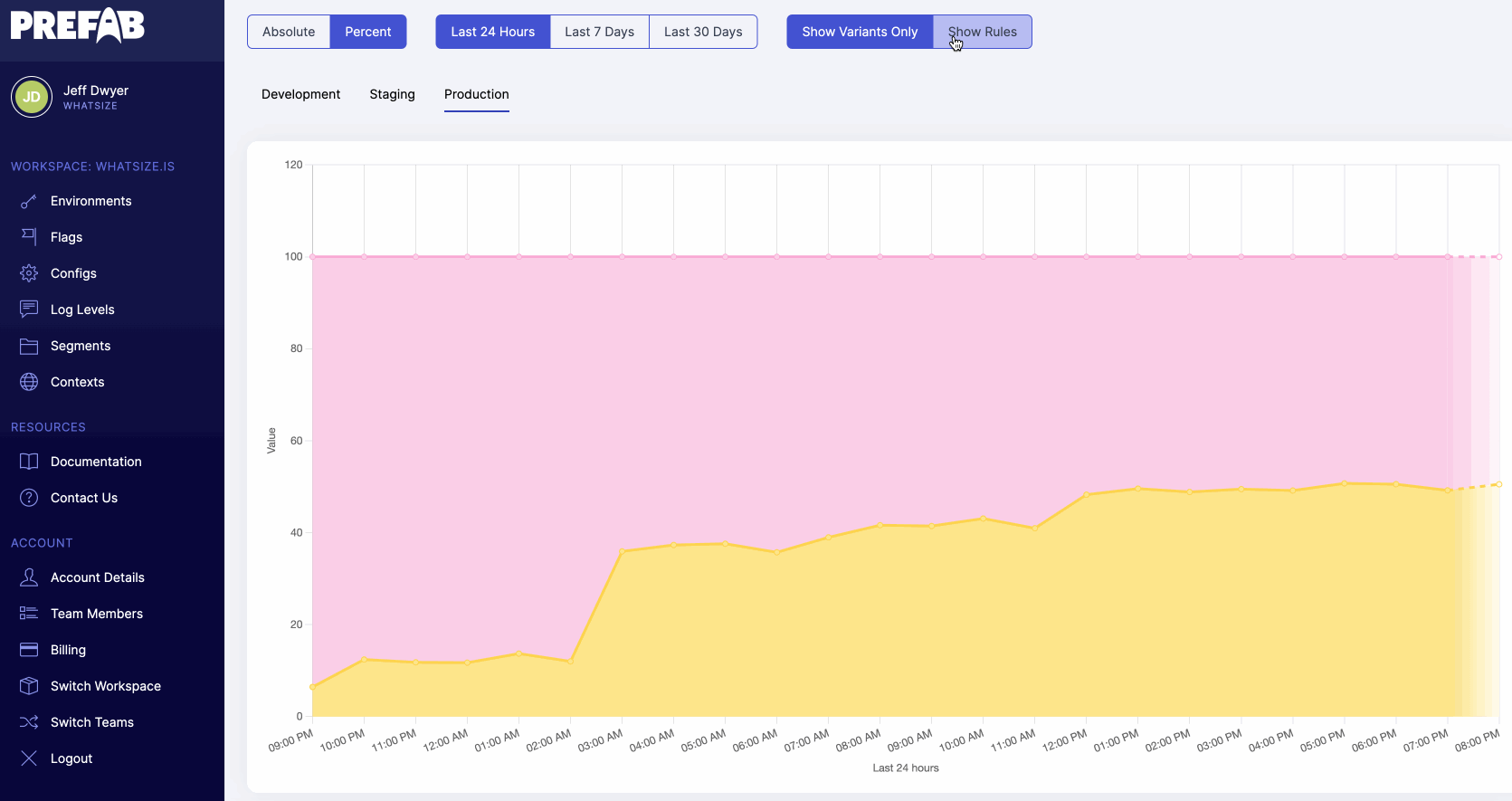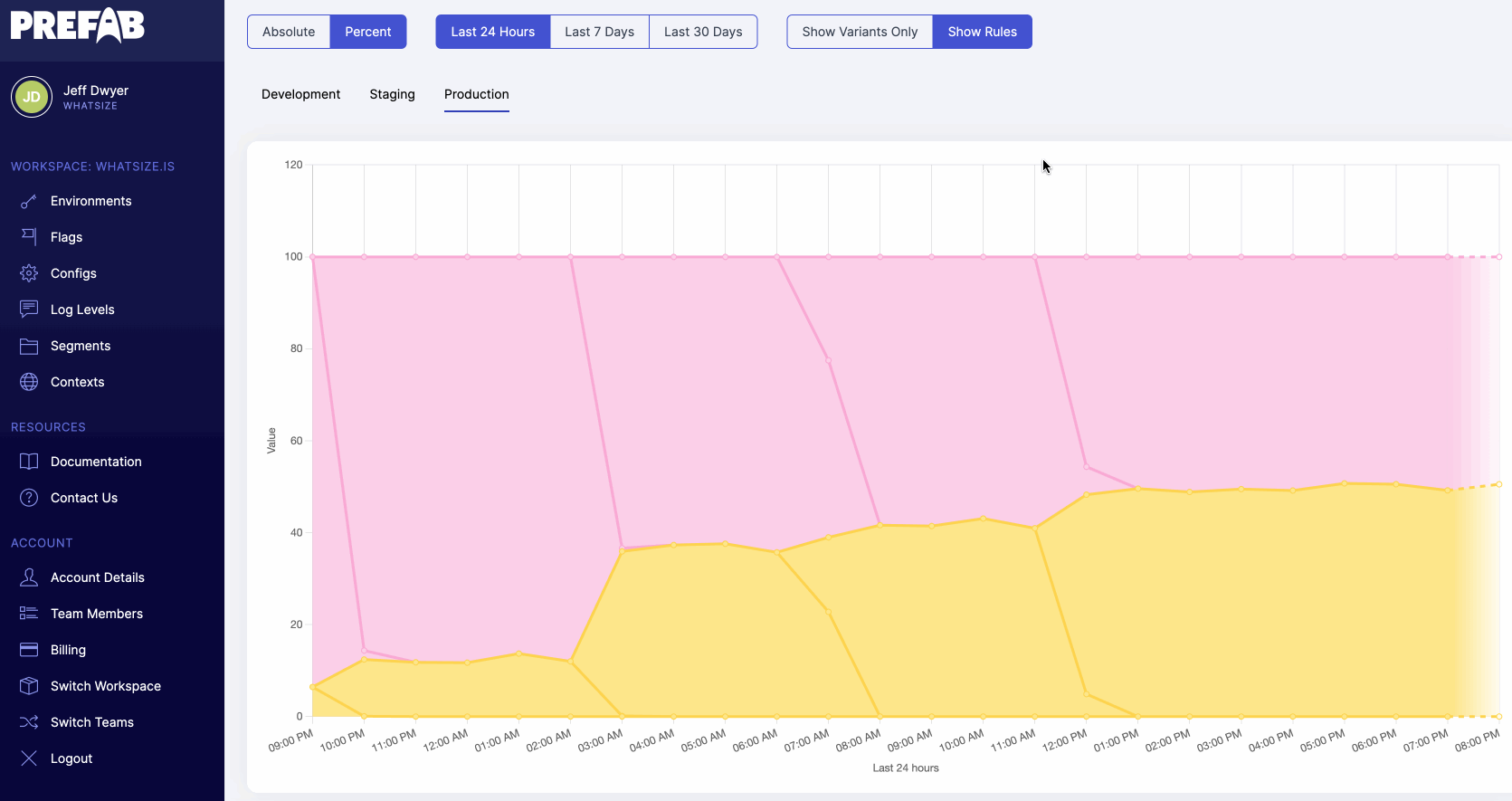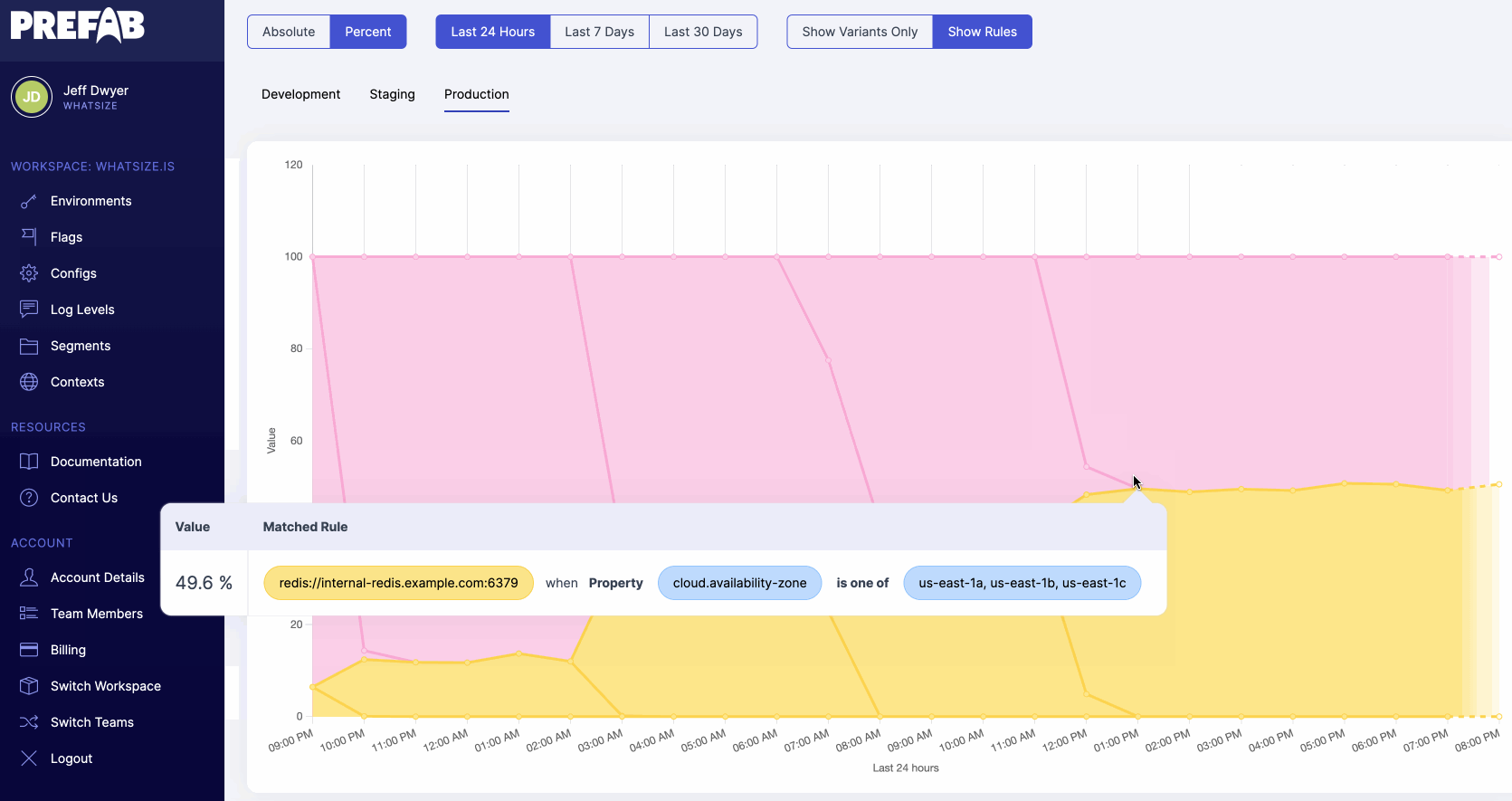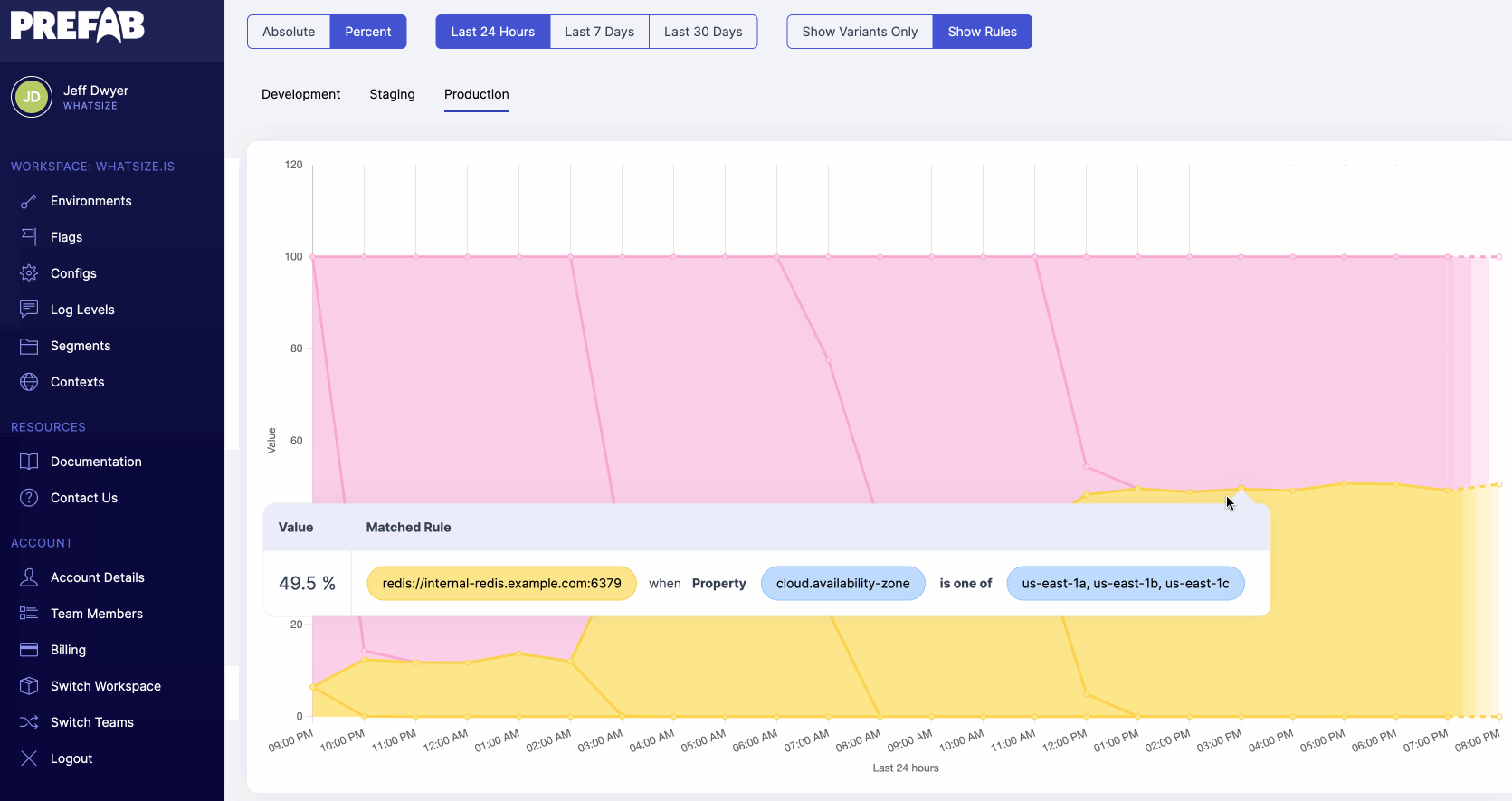
4. What Value is it in Production?
How many times have you had to SSH into a production server to check the value of an environment variable? Or had to ask an ops person to do it for you? It's a pain, it's gross, it's a security risk. Environment variables: the really important configuration variables that you can't actually see or audit.
Partly, this is from scattered defaults, but mostly, this is from the complexity of the systems we've built to inject these variables and the lack of telemetry on their usage.
- Issue: Assessing the environment variable values in production is cumbersome, requiring system access and specific commands.
- Impact: This adds complexity to troubleshooting and configuration verification in live environments.
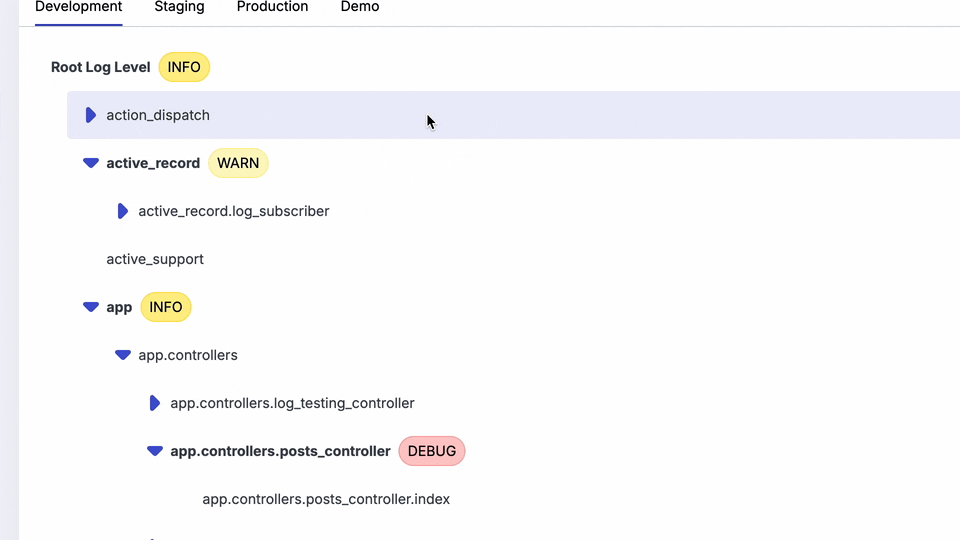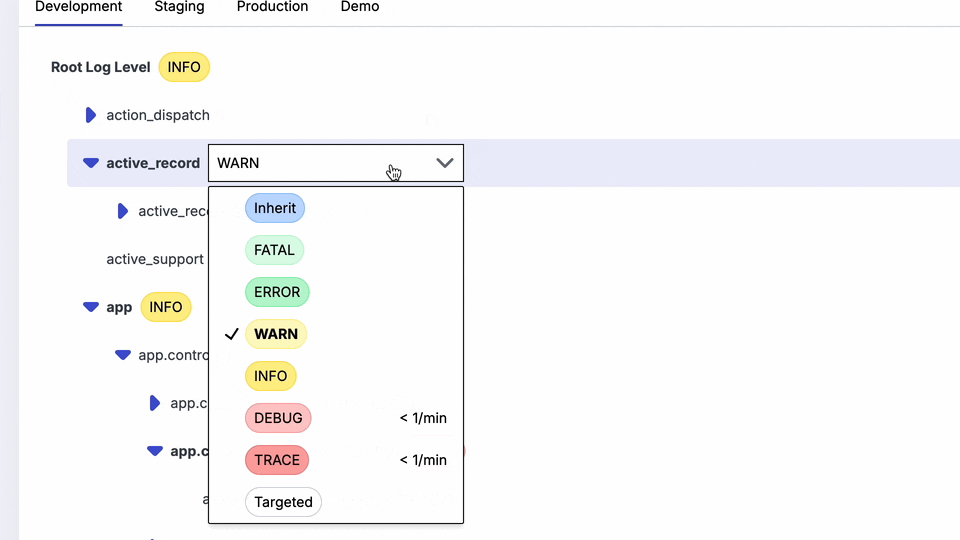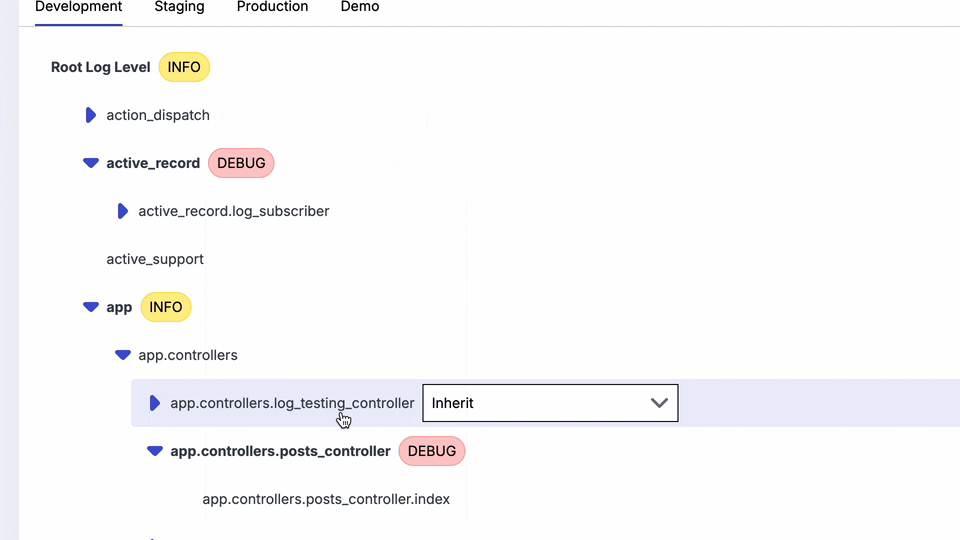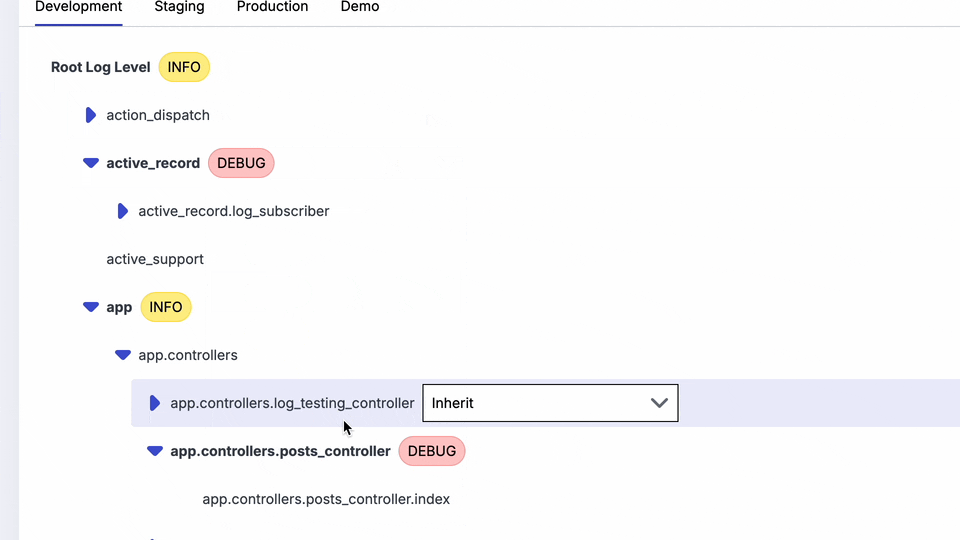
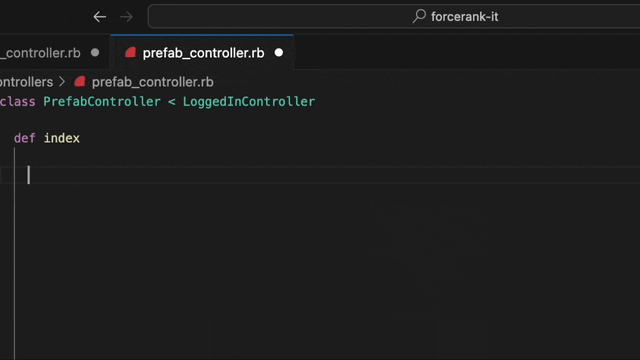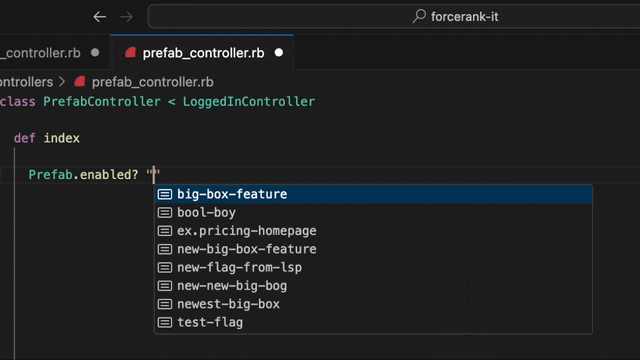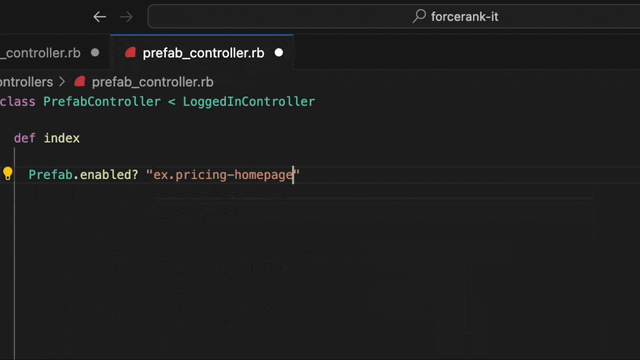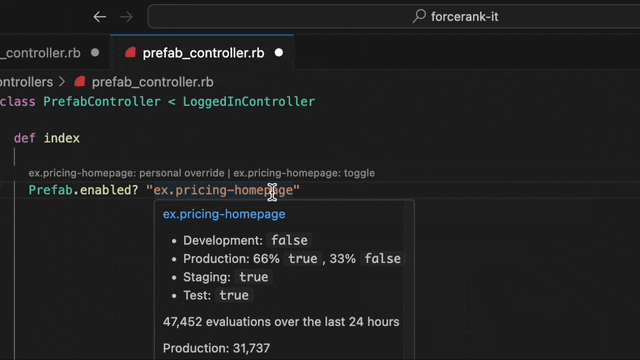
Why can't I use a CLI to see this? Why can't I just hover in my editor and see the configuration in each environment and the actual runtime values?
~/app (main) $ prefab info
? Which item would you like to see? postgres.db.ip
- Default: 127.0.0.1
- Development: [inherit]
- Production: `POSTGRES_DB_IP` via ENV
- Staging: `POSTGRES_DB_IP` via ENV
- Test: [inherit]
Evaluations over the last 24 hours:
Production: 5
- 100% - 10.1.1.1
Staging: 2
- 100% - 10.11.12.13
Development: 25
- 100% - 127.0.0.1
No more ssh and printenv; I should just be able to do this from the comfort of home.
5. Refactoring Environment Variables is Terrible
Want to change an environment variable name? Good luck. Enjoy slacking everyone that they need to update their .env file in every repo.
Want to spin up a new application? Copy pasta the old .env around and let the duplication party begin.
Want to update the default across all your apps? Good luck.
- Issue: Each
.envis a massive duplication of our configuration, and this makes refactoring hard. - Impact: We get crufty code.
6. Cross Language Incompatibility
In truth, Rails has a decent story around all of this for a monolith. And various languages and frameworks have good approaches. But, what's that you say? You have a node app and a rails app? A Java app, too? And you'd like to... gasp... share a configuration value across them all? Sorry, mate, you're on your own.
- Issue: Custom configuration libraries for each language create a lack of consistency and interoperability.
- Impact: Lack of interoperability meets cut-overs to the new
redis.urineed to happen on a per language basis and require understanding the configuration system (or systems) for each repository.
7. Question of Scale: How Many is Too Many?
How many environment variables is the right number? Ten or twenty is certainly fine. 100 sure feels like a lot and makes things ugly. 1000? More? No, thank you.
But... how many aspects of my system would I like to be configurable? Well, if you take off the shackles of having to jam everything into an env var, I suppose I'd actually like to configure lots of things. Should my http timeout be the same for every single request? Actually, I’d like to tune that at a fine-grained level. But I sure as heck am not going to do that if there is one env var per config. TIMEOUT_AUTH_SERVICE_FROM_BILLING_SERVICE=5000 is madness.
- Issue: The way environment variables work fundamentally encourages a small number of variables, which is at odds with the desire to have a highly configurable system.
- Impact: We build systems and libraries without as many knobs and levers as we'd like, and this limits our options for real-time adjustments to production issues.
8. Updates: Slow and Forgettable
Most places I would expect an hour or two. Yes that's crazy, but yes that's the reality. Usually this is a ticket into your devops team and then they have to go update the value in a configmap or something. (I will admit that if you're on heroku this probably takes 1 minute. This is how it should be!)
Changing a variable should be instant, but we have these variables locked into a system that, for most of us, is slow to update.
- Issue: Updating environment variables can be time-consuming, particularly in larger and more complex systems.
- Impact: Slow MTTR when issues could be fixed by configuration changes.
9. Secrets Management Requires a Different System
Secrets are just configuration too, or they should be, albeit with more permissions and confidentiality. However, our code needs to know the values just like it would any other variable. Instead, almost all of us have to operate two totally separate tools/processes for managing secrets and configuration.
- Issue: Managing sensitive data often requires a separate system from standard environment variables, adding to the complexity of configuration management.

I should be able to see all my configuration in one place, secrets, too. Sure, secrets are confidential and should be encrypted, but that doesn't mean I shouldn't be able to understand that my applications are using them.
Conclusion
Environment variables have got us a long way, but we can do better, and indeed, lots of organizations have built sophisticated dynamic configuration systems that address all of these issues. The future just isn't evenly distributed. Or... hasn't been until now.
The key elements of a better system are:
- A single view of all of my configuration
- Typed values like: string, bool, duration, arrays, etc.
- Defaults that are easy to override for local dev
- Easy to share configuration between projects
- Telemetry on what values are actually being used in production
- Interoperability with Terraform / IaaS / Kubernetes / Existing Secrets Management
- A system that supports secrets as well as configuration
As I said, to my knowledge, the best examples of systems that support all this typically come from internal tools at large companies. HubSpot talks briefly about their in How we deploy 300 times a day. Amplitude covers the architecture decisions of theirs in Using DynamoDB for Dynamic Configuration and Netflix's open source Archaius has a lot of the underpinning pieces, though no help on the UI. And, of course, we have Prefab, which is our attempt to bring this to the world.
What's Next?
I think we're a fair way along this journey here at Prefab, and we're excited to share what we've learned and what we've built. I'd love you to check out our dynamic configuration and let me know what you think.
To a world of better config for all 🚀