From Debug to Panic - Comparing Log Levels Across Top Languages

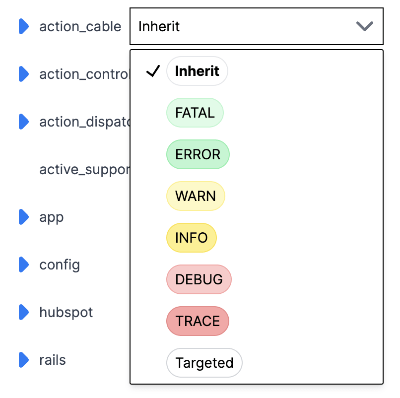
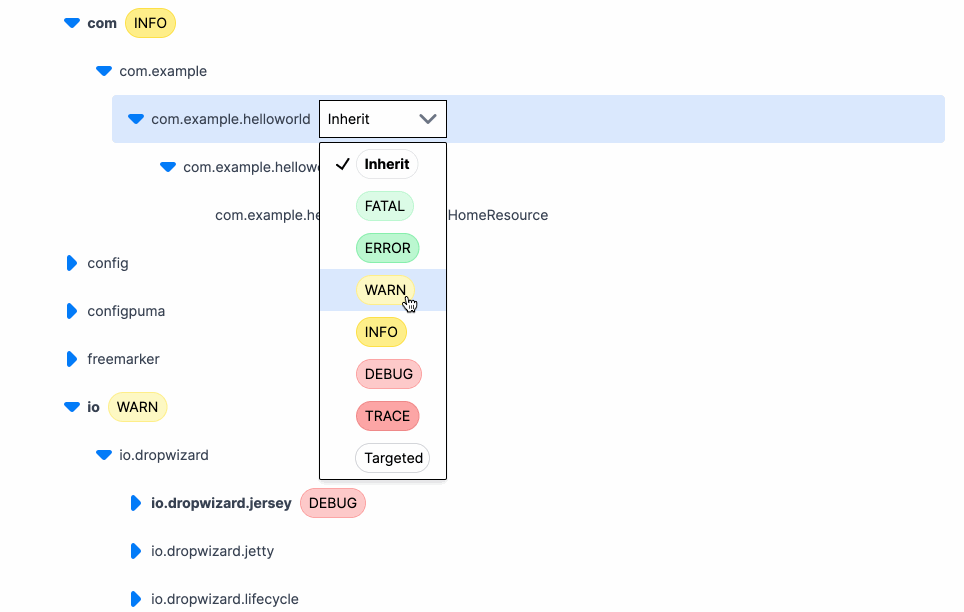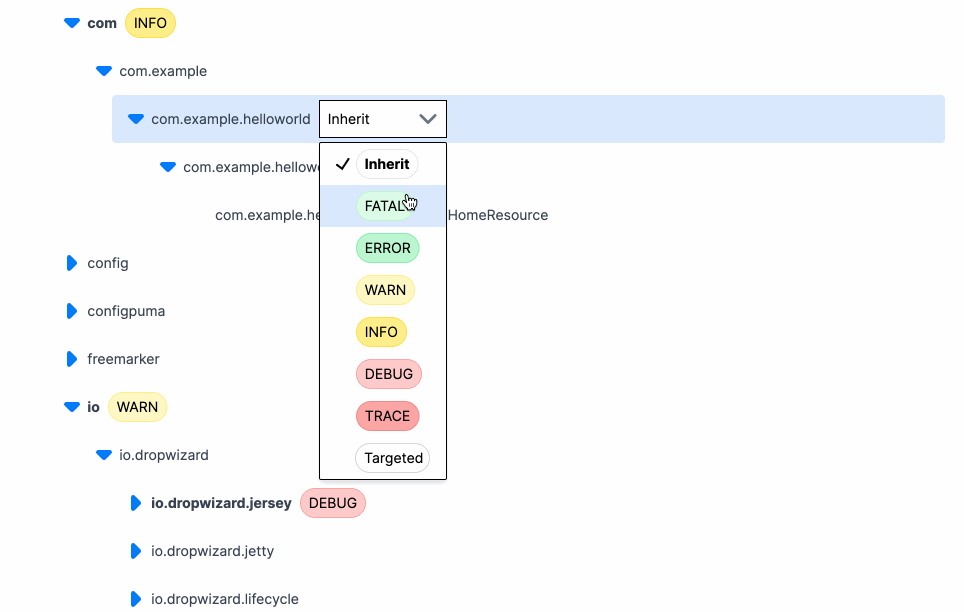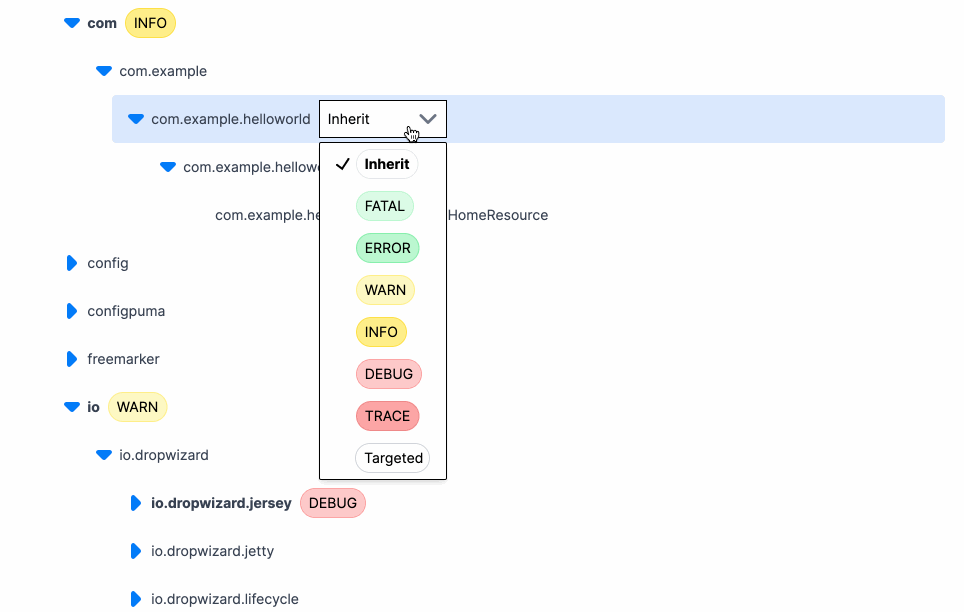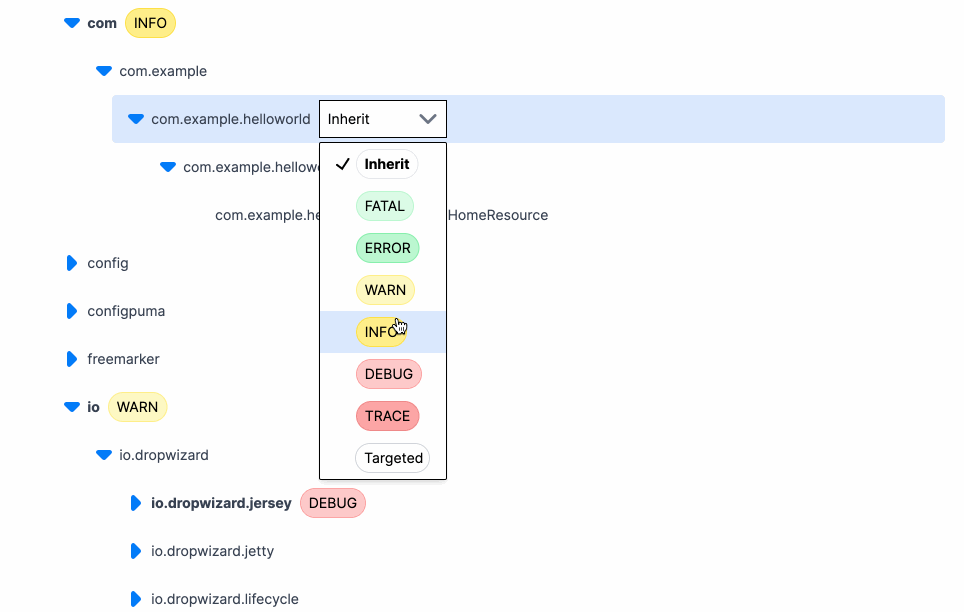
Log levels exist to help developers filter through application logs and focus on relevant information. But what levels are available in each language? I recently looked into this because one of the features of Prefab is that it lets you change your log levels on the fly. To build this, we needed to offer users a dropdown of log levels to choose from. But which levels to show?
You might think that providing a list of levels to choose from should be straightforward. We're all trying to achieve the same thing with logging, so I'm sure there's a nice standard solution, right? Well, no. In this blog post, we'll take a lighthearted look at the log levels available in popular languages and frameworks, comparing their similarities and differences, and pointing out the quirks that make them unique.
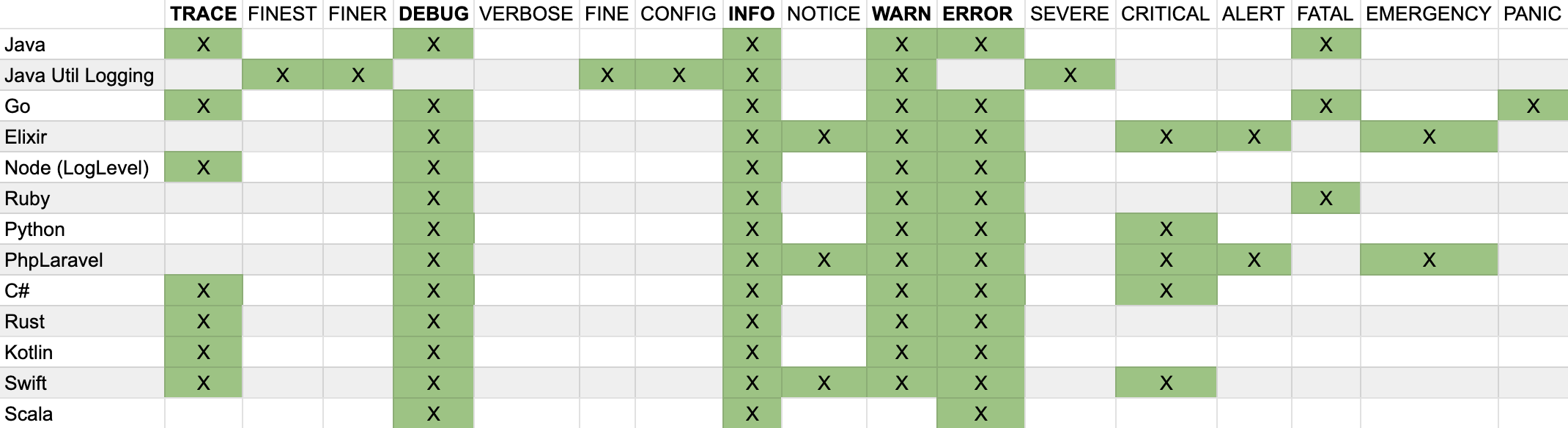
A Tour of Log Levels:
- Java
Ever-popular, Java has a clear-cut set of log levels:
Trace,Debug,Info,Warn,Error, andFatal. Straight to the point, Java keeps things simple and functional... as long as you are you using a Simple Logging Facade for Java (SLF4J). Java likes a Facade Pattern. - Java Util Logging
If you make the newbie mistake of trying to use the built-in
java.util.loggingyou're in for a surprise. This package brings us one of our most esoteric set of levels:Finest,Finer,Fine,Config,Info,Warn, andSevere. A fine dining experience of log levels, you can smell the overthinking from a few decades away. Presumably this came about from some deep thinking thatFinenessis the right way to describe the levels, whereasDebugdescribes the action you might take upon them. 20 years on, we're still not sure what to do withFinestlogs. - Go
A language known for its simplicity and efficiency, offers a slightly extended set of log levels:
Trace,Debug,Info,Warn,Error,FatalandPanic. This is the same as the Java set, but we've addedPanic. This is because Go wants to make it clear that it's born of real world concerns. Sometimes your can't simply die and have that be the end of it. When you're running the Internet like Google is, sometimes you need toPanic. If you are using Kubernetes, logging atPanicwill also send a Google Wave notification to Larry Page. - Elixir
Speaking of real-world reliability, Elixir spices things up with a unique set of log levels:
Debug,Info,Notice,Warn,Error,Critical,Alert, andEmergency. This is Elixir’s way of reminding you that it runs on top of Erlang and was achieving 6 nines of uptime when you were still writing “Hello World”. It has thought more about error handling that you ever will, which is why logging atEmergencyactually increases America’s DEFCON by 1. - Node.js
The popular JavaScript runtime sticks to it's philosophy of: the first step in doing X is choosing between 6 different basically equivalent NPM packages. LogLevel keeps it real with
Trace,Debug,Info,Warn,Errorbut there's no reason not to getSillyand go with NPMLog which offersSilly,Verbose,Info,HTTP,Warn&Error. I didn't addSillyto the matrix below because that's just plain silly. - Ruby
Known for its elegance, Ruby has a slightly different set of log levels:
Debug,Info,Warn,Error, andFatal. They're the same as Java, but with noTrace. This is because Ruby wants you to enjoy yourself and if it's come toTracethings have already gone too far and you should take a break and meditate upon the problem. - Python
Python, the versatile language, keeps it simple with just five log levels:
Debug,Info,Warn,Error, andCritical. You’ll note that this is the same as Ruby, but withCriticalinstead ofFatal. Python is a battlefield medic and can't be calling things dead if it's possible there's a chance they could be revived. - Php/Laravel
Laravel, the popular PHP framework, can’t be contained to the big 5. It offers
Debug,Info,Notice,Warn,Error,Critical,Alert, andEmergency. Sometimes Php gets a bad rap, so it wants you to know it’s prepared for any situation that might arise. What's the difference betweenInfoandNotice? Why isAlertmore serious thanCritical? Php knows, but it's not telling. - C#
A powerful language from Microsoft, C# opts for a set of log levels similar to its peers:
Trace,Debug,Info,Warn,Error, and (like Python)Criticalinstead ofFatal. It's a solid, no-nonsense approach. Microsoft's version of Java needed to differentiate itself somehow, but didn't have any ideas of its own so stole one from Python. - Rust
A systems programming language, Rust has a minimalistic set of log levels:
Trace,Debug,Info,Warn, andError. Rust knows that keeping things simple is key. It doesn't require anything more serious thanErrorbecause nothing can go wrong in properly written Rust code. - Kotlin
This modern and expressive language JVM language, keeps its log levels consistent with its Java roots:
Trace,Debug,Info,Warn, andError. It's clear that Kotlin values simplicity and familiarity. It removedFatalbecause it's not a fan of drama. - Swift
Swift, the language for iOS development, has a concise set of log levels:
Trace,Debug,Info,Warn,Error, andCritical. Swift ensures that developers can easily manage logs while building apps for Apple devices. Swift wants to make sure that your Fart Sound iPhone can properly log atCriticalwhen notifications are disabled. - Scala
No stranger to thinking differently, Scala takes a hardline approach to logging, only allowing us:
Debug,InfoandWarn. You might've expected the superset of all possible Log Levels for Scala, since Scala generally has the superset of all possible programming idea, but at some point enough is enough and they landed on the simple union of all log levels. And frankly, maybe that's all you need.
Conclusion:
After examining the log levels across various languages and frameworks, we were able to pick a core set of log levels that should work well with Prefab. The common log levels we identified are Trace, Debug, Info, Warn, and Error. These levels cover the essential needs of developers, allowing them to effectively debug their applications and handle critical notices.
The good news is that no language decided to place Error before Warn or Info before Debug. This means that a general ordering of log levels can be established and client specific mappings can be created to paper over the differences. These core log levels are universal enough to provide a solid foundation for Prefab's on-the-fly log level changing feature.