A Redis Cache Migration With Feature Flags

Introduction:
Feature flags are phenomenally useful, but most examples are from a product perspective and focus on the user context. That's great, but developer use cases are equally powerful if we make the tools understand the engineering specific contexts. In this post, we'll explore what that looks like by walking through an example of a redis cache migration. /imagine canadian geese migrating with the power of rocketships.

How to Manage a Redis Migration Safely Using Feature Flags
For this example, let's imagine that we're using 3rd party Redis provider and we've been unhappy with the reliability. We've spun up a helm chart to run redis ourselves and we're ready to migrate, but of course we want to do this in a way that's safe and allows us to roll back if we encounter any issues.
We're using this Redis as a cache so we don't need to worry about migrating data. It is under heavy load however and we don't trust our internal Redis just yet, so we'd like to move over slowly. Let's imagine we've set the new Redis up in a particular availability zone, but we aren't sure what that will mean for latency.
Here's the migration plan we've come up with, we'd like to take 10% of the nodes in US East A and point them at the internal Redis. If that goes well, we'll scale up to the entire AZ. If that goes well, we'll move the rest of the nodes in this availability zone. Then we'll move on to US East B and finally US West. The diagram here shows Step 1 of the rollout pictorially.
Why?
- 10% of Nodes in the same AZ will test basic functionality
- 100% of Nodes in the same AZ will start to test performance & load
- Adding US East B will test cross AZ latency
- Adding US West will test cross region latency
So, how do we do this?
Step 1: Code the Feature Flag
For this example let's use the connection string as the value of the feature flag. We can have the current value be redis://redis-11111.c1.us-central1-2.gce.cloud.redislabs.com:11111 and the new one be redis://internal-redis.example.com:6379. To use the value, we'll just modify the creation of the Redis client.
In simple terms, this will look something like:
String connStr = featureFlagClient.get("redis.connection-string");
return RedisClient.create(connStr).connect();
Implementing this is a bit more complex. The Redis connection is something you'll want to create as a Singleton, but if it's a singleton it will get created once and won't change until we restart the service. Since that's no fun, we'll need a strategy to have our code use a new connection when there is a change. We could do this by listening to Prefab change events, or we could use a Provider pattern that caches the connection until the connection string changes. Here's a Java example of the provider pattern:
Full Code of Provider Pattern
@Singleton
public Provider<StatefulRedisConnection<String, String>> getConfigControlledConnection(
ConfigClient configClient
) {
record ConnectionStringConnectionPair(
String connectionString,
StatefulRedisConnection<String, String> connection
) {}
AtomicReference<ConnectionStringConnectionPair> currentConfigurationReference = new AtomicReference<>();
return () ->
currentConfigurationReference.updateAndGet(connPair -> {
String currentConfigString = configClient
.liveString("redis.connection-string")
.get();
if (connPair == null || !connPair.connectionString.equals(currentConfigString)) {
return new ConnectionStringConnectionPair(
currentConfigString,
RedisClient.create(currentConfigString).connect()
);
}
return connPair;
})
.connection;
}
Now, the bigger question. How do we:
- Configure our feature tool to randomize the 10% of nodes.
- Target the feature flag to just the nodes in US East A.
Step 2: Giving the Feature Flag Tool Infra Context
A brief detour into some context on "context". Most feature tools think of context as a simple map of strings. It usually looks something like this:
Typical Context for Product
{
"key": "1454f868-9a41-4419-a242-d5a872ec5f04",
"user_id": "123",
"user_name": "John Doe",
"team_id": "456",
"team_name": "Foo Corp",
"tier": "enterprise"
}
This starts out fine, but it can start to feel icky when you start to add more and more things to the context. Is it ok to push the details of our deployment like the host.id in here? How much is too much? This is the "bag o' stuff" model and it's a bit like a junk drawer.
The bigger issue however is whether the tool allow us to randomize by something other than key? Because our rollout plan is to test the new Redis on 10% of nodes, not 10% of users. If your feature tools isn't written with this use case in mind this can be hard or impossible to do.
So yes, as developers, we need more information. Oftentimes we are operating with a user and team context, but we also need to know about things like the deployment, the cloud resource, and the device. A proper context or "multi-context" should look something like this:
Context For Developers
{
"user": {
"key": "1454f868-9a41-4419-a242-d5a872ec5f04", // a unique key for the user / anonymous user
"name": "John Doe",
"id": "123" // for non anonymous users
},
"team": {
"key": 1,
"name": "Team 1",
"tier": "enterprise"
},
"device": {
"ip": "19.122.43.123",
"locale": "en_US",
"appVersion": "1.0.1",
"systemName": "Android",
"systemVersion": "11.6"
},
"request": {
"key": "c820567a-9f2d-4b3d-85e5-9ff4132d0e08", // a unique key for the request
"url": "http://production.example.com/user/123",
"path": "/user/123"
},
"deployment": {
"key": "pod/user-service-bcddb8c8d-mxz6v",
"namespace": "production",
"instance-type": "m4.xlarge",
"instance-id": "i-0a5b2c3d4e5f6g7h8",
"SHA": "27bdd4f9-3530-46a6-8188-9d90467f086e"
},
"cloud": {
"key": "i-07d3301208fe0a55a", //host-id
"platform": "aws_ec2",
"region": "us-east-1",
"availability-zone": "us-east-1a",
"host-type": "c4.large"
}
}
This is a lot more information, but it's also a lot more useful and structured. The key piece here is that we are specifying cloud.key as the host id. This is the unique identifier for the host that we can use to randomize the rollout.
We can use this as our "sticky property" in the UI. This is the property that the client will use to randomize on. The host doesn't change so each node will stay in the bucket that it is originally assigned.

Step 3: Targeting the Feature Flag to and Availability Zone
The next step is simply to add a targeting rule. We should have all of the context attributes available to select from in the UI. We can select cloud.availability-zone and set it to us-east-1a.

Altogether that looks like this:

The feature flag is now enabled for 10% of the nodes in us-east-1a. If the node is not in that availability zone, it will get the default value.
Step 4: Observe Our Results
It's always nice to observe that things are working as expected. What percent of all of the nodes are receiving the new Redis connection string?
As we go through the steps of our rollout plan and verify performance and latency along the way, we should see the number of evaluations increasing for our internal redis install.

Each bump in the graph should be related to our incremental approach to changing the rollout. If there are changes that aren't related, we may need to look into our assignment of the cloud.key since that is how we are randomizing. We should expect that the percentages here do not exactly match the percentages we set. For example if we split 80/20 and we have 50 hosts, each of them will have a 80% chance of being in the group, but we might certainly expect to see 38-42 hosts in that group due to random distributions.
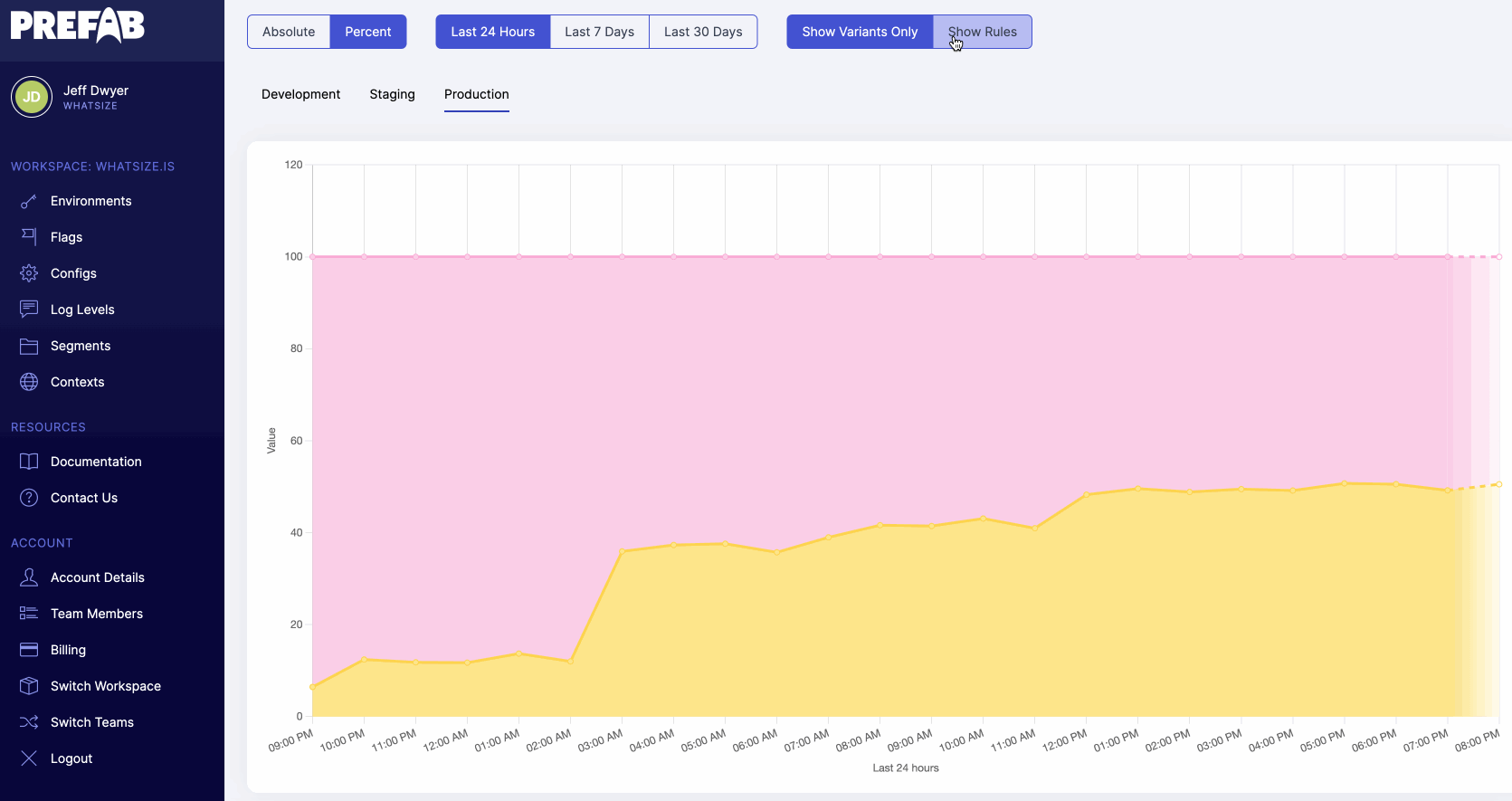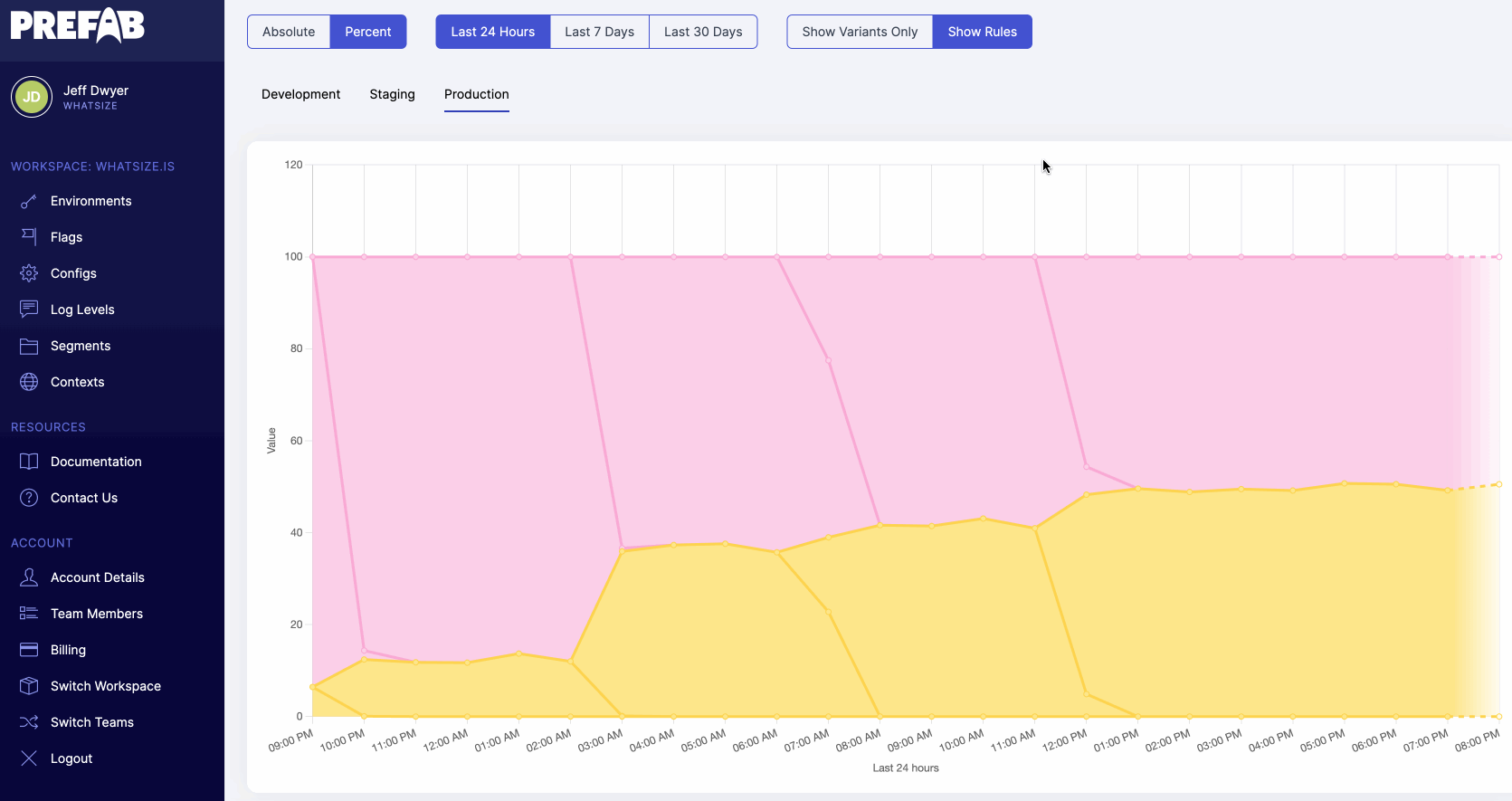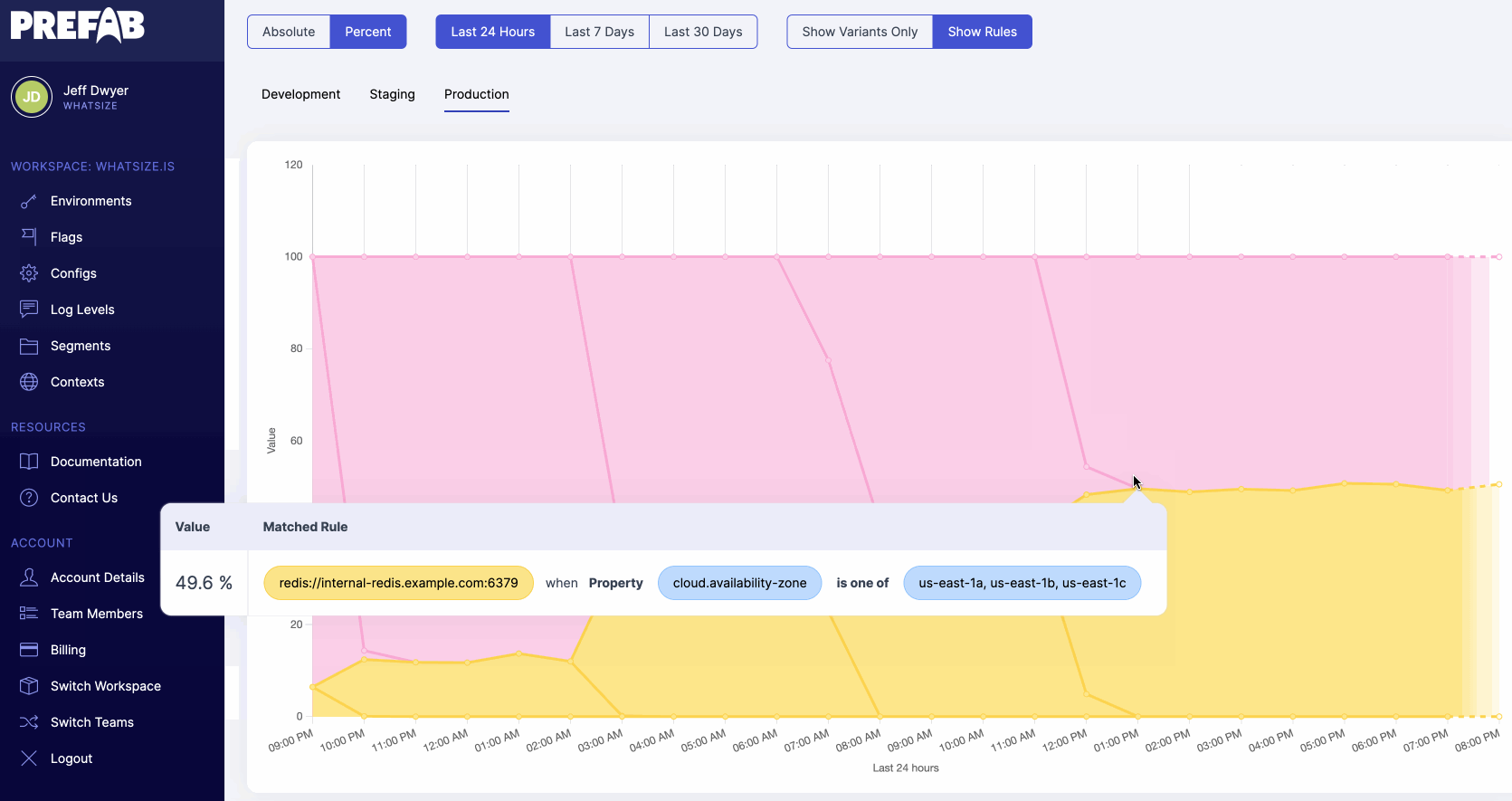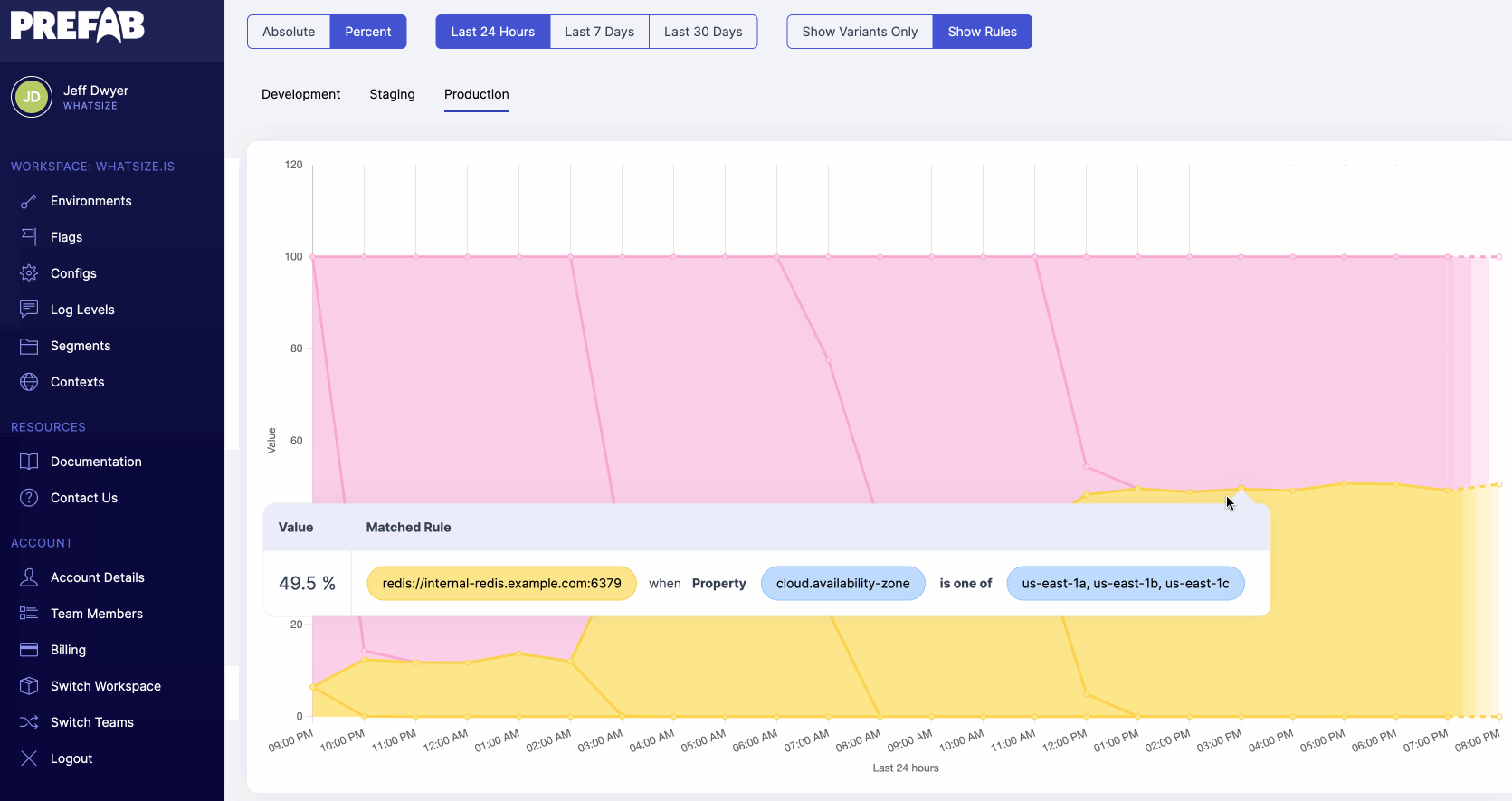
If we want to dig into the numbers we're seeing here, we can select "show rules" to see all configuration changes on the chart and determine which feature flag rules lead to our output numbers.
Summary
This is a simple example, but it shows how we can use feature flags to manage a migration in a safe and incremental way. It also shows how we can use multi-context feature flags to make feature flags more powerful for developers and engineers.
Finally, we see how nice it is to have a feature flag tool that gives us insight into breakdown of our evaluations and the ability to dig into the numbers to see what's going on.