Log Levels Are Useless, Or Are They…

What should you log? How much should you log? What level should you log at? It's a question that's been asked for ages and there's no shortage of opinions on the subject.
Thom Shutt has an interesting post here that I think does a good job of describing the “bear case” for logging. Part of his recommendations are:
- Only log errors
- Throw away
warn,infoanddebuglevels
If that's surprising to hear, his reasoning for this recommendation is pretty solid:
When was the last time you ran Production at anything other than Info? Is changing the level a quick process that everyone on the team knows how to do?
The expected answer to his question is of course, that most of us aren't changing log levels very often, and that matches my obvervations. So it's a good point, if you aren’t able to to easily change the system and get out debug level… these lines really are just noise and you might as well delete them.
The Assumption
The underlying assumption here, is that changing the log level is a pain in the butt and takes a while. I can’t see your face, but I’m guessing you’re nodding. Most places I’ve worked, changing the log level means:
- Finding and changing some xml or yaml file
- Commit, push
- Wait for PR approval
- Build and deploy to staging then production
- $Profit
- Do it all again to revert your change
And depending on the language and framework, you may only be able to change the log level for the entire application at once.
Let’s be wildly optimistic and say this takes you 30 minutes from commit to production and assume we set the right logger in our first try. Even if that’s the case, we’ve still lost an hour of our day to maybe get the debug information we were hoping for.
So in this world, throwing away log levels and only doing errors makes a lot of sense.
A Better Way
So is this assumption true? Are log levels fundamentally hard to change at runtime? No, they're not.
Or at least they don't need to be anymore.
Here’s what changing a log level looks like using Prefab. Click, change, done.
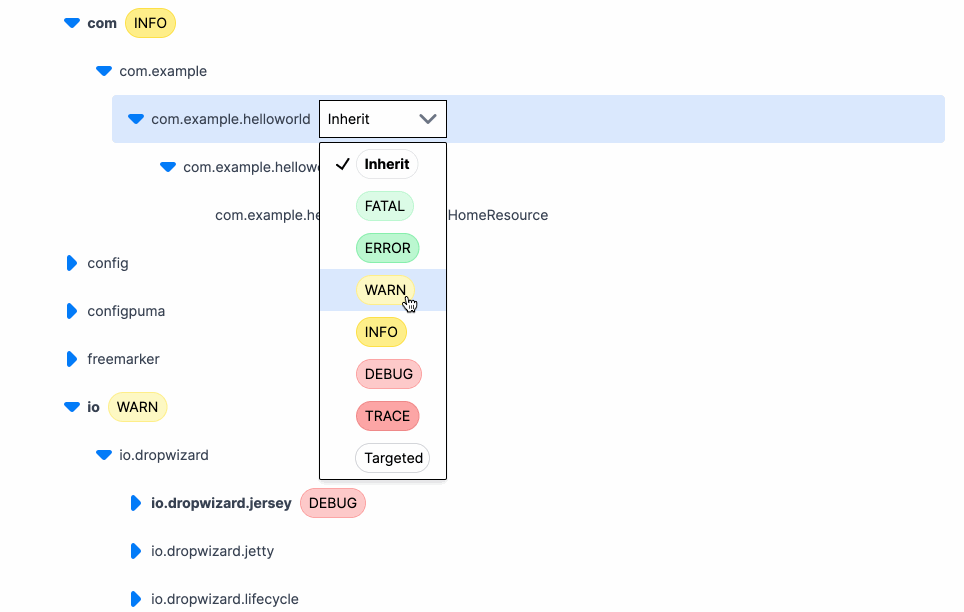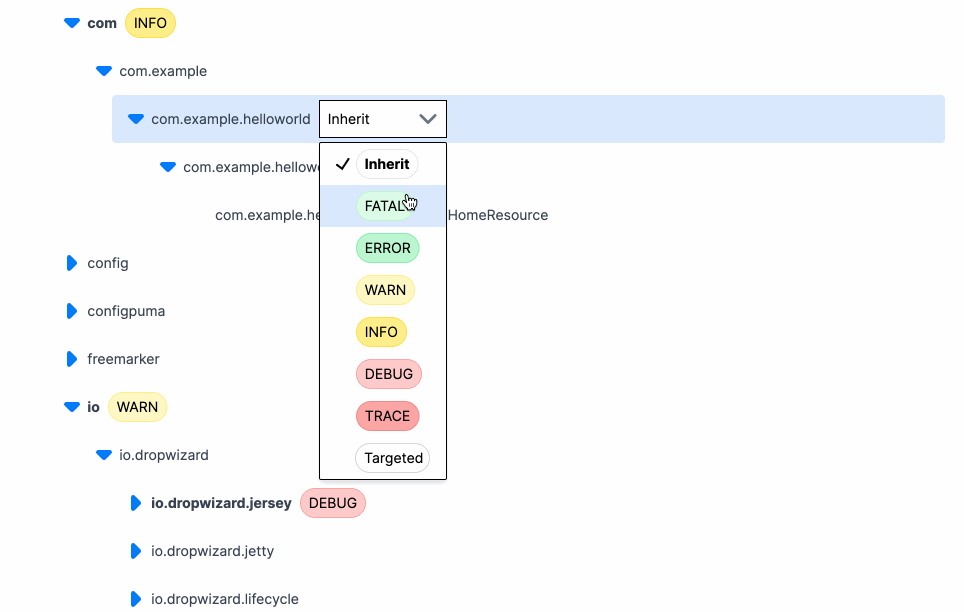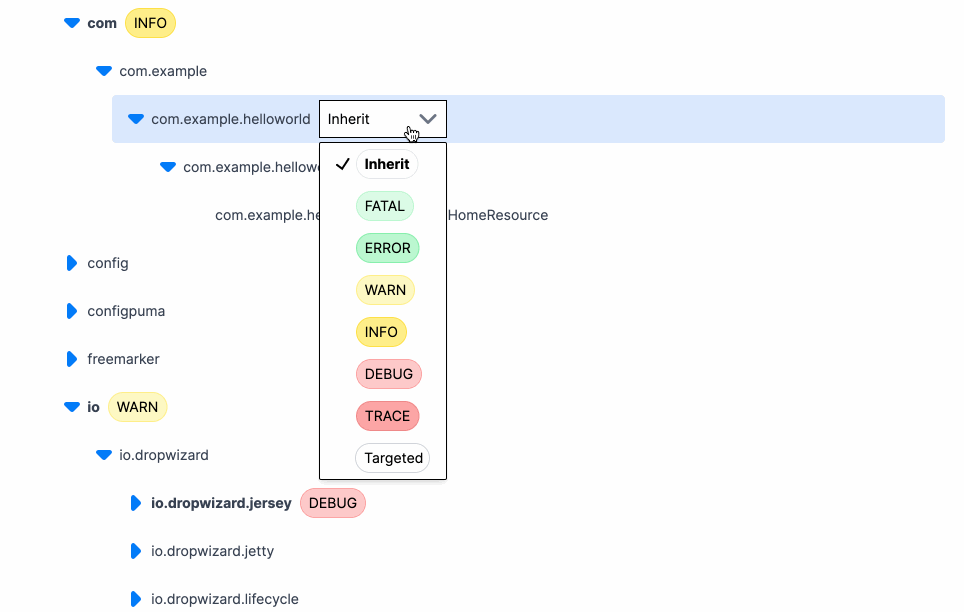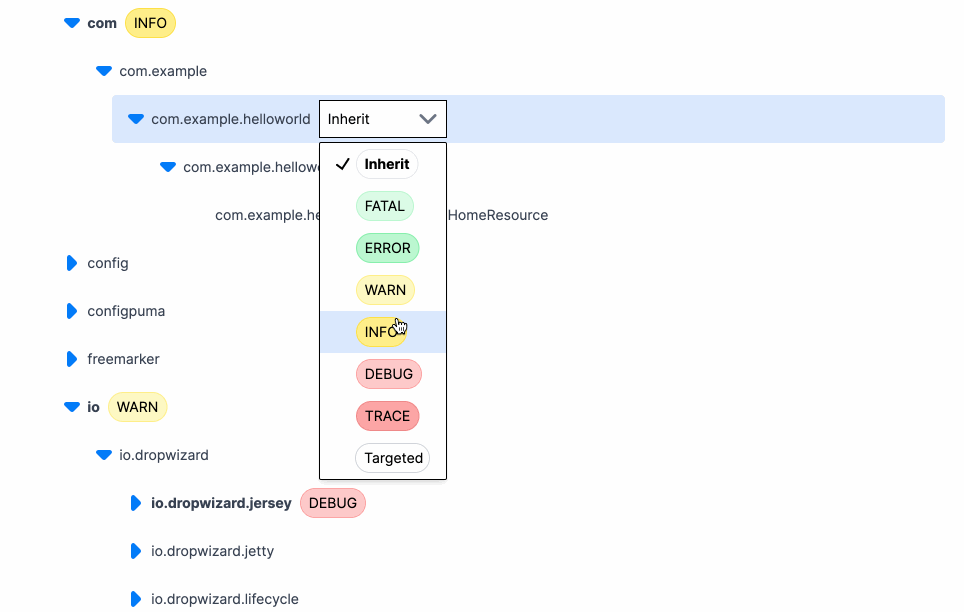
And that’s it. The log levels update in realtime for whatever package or class you select. The logger is a hierarchical tree, so we set the level wherever it's convenient and everything below it will inherit that level.
That's pretty amazing, but the next trick takes it to a whole other level.
Prefab also lets you target logs so that you only get debug for a particular user. To do this you just select "Targeted" log level add criteria like you would for a feature flag and instantly you can see debug logs for just a single user.
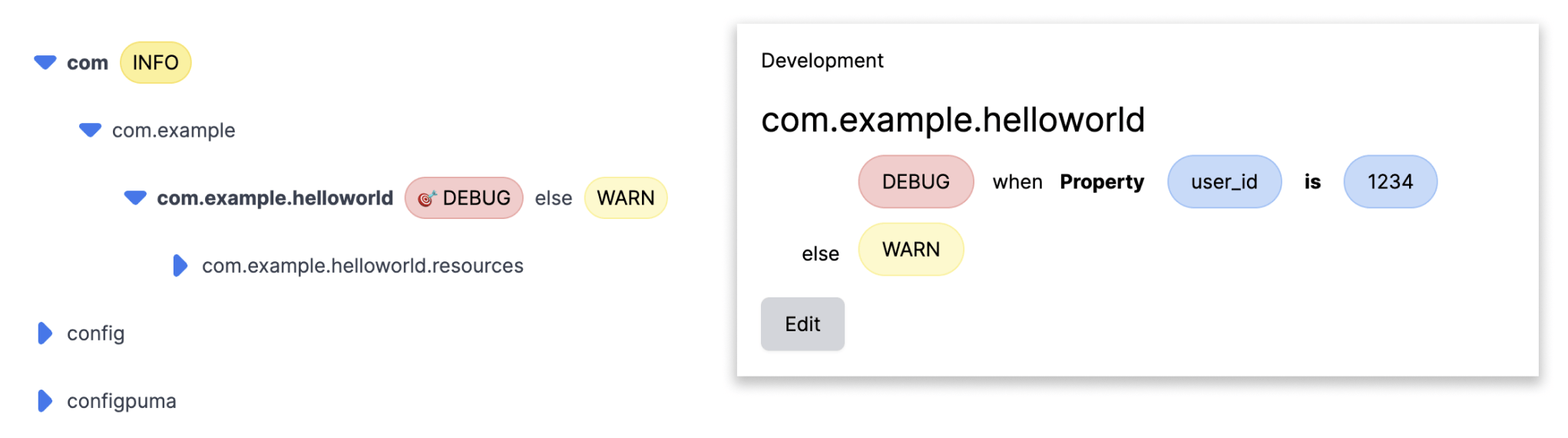
What This Means
So, if the assumption we laid out above is false, the next question is
How does this change what we should log?
If the inability to change log levels leads us to a mindset of only logging errors. What happens when we can change log levels in seconds? What happens when we can only log for a given user, team or transaction?
Mean Time To Recovery (MTTR)
You're probably familiar with the DORA metrics so I won't go deep here. But here's a quick definition of MTTR from CodeClimate
The Mean Time to Recovery (MTTR) measures the time it takes to restore a system to its usual functionality. For elite teams, this looks like being able to recover in under an hour, whereas for many teams, this is more likely to be under a day.
If you're looking to meaningfully improve MTTR, it's hard to think of something more useful than the ability to instantly turn on debug level logging for a single user across your apps. The pager comes in, the bug tracking system explodes. You've got great metrics in your observation tool, but... why is this happening? What data is causing your system to start malfunctioning. Why shouldn't we give our on-call engineers the ability to instantly see the details of what's really going on and start to debug?
How Does it all work, or "Dynamic Configuration Brings Good Things to Life"
The enabling technology here is Dynamic Configuration. People fall in two camps on this: "haven't heard of it" and "can't live without it", but for the most part, this tech is something that has been the province of big tech (Twitter, Netflix, Robinhood, Amplitude). So, if you're not familiar with it, let's introduce the concept.
Almost all apps use some form of static configuration, this is when our apps read a property file or an environment variable. This looks like: Properties.get("http.timeout") or ENV["DATABASE_PORT"].
Dynamic configuration works just the same way DynamicConfig.get("http.timeout") but of course the value returned is... dynamic. We can set a new value a UI somewhere and each time we evaluate, we’ll get the latest version. A proper dynamic configuration system focusses on extremely high reliability and each lookup should be as fast as static configuration. At a high level the implementation ends up being a local Hashmap for each running instance and something that listens to a change stream that updates the map.
So how does dynamic configuration help us with logs?
Well, it turns out that your logger libarry also has a Hashmap of Logger -> LogLevel for each class that can log.
Each time we call logger.info the logging library is going to look up the current log level to decide whether to log.
Long story short, if we store these Logger -> LogLevel mapping in our config system and update the logger on changes, we suddenly have the ability to change from warn to debug in milliseconds instead of hours.
Adoption
Learning to use this tool most effectively is a cultural change for an organization and one that will make some people uncomfortable at first. But it's a change that will pay dividends and the great news is that you can use it out of the box with your existing logging immediately.
Let's take an example. If you saw this in a PR, would you tell the engineer to remove it? A lot of people would. It looks like an artifact of the development process. It was surely useful, for local testing, but if we don't use debug in production it's just noise and should be removed.
def charge(user, amount)
balance = get_balance(user)
min_balance = get_min_balance(user)
logger.debug("#{balance > min_balance ? "Will" : "Will Not"} Bill amount #{amount} because #{balance} > #{min_balance} for User #{user}")
if balance > min_balance
charge_user(user, amount)
else
end
But this reasoning all gets stood on it's head if we can now instantly turn it on for a single problematic user for an hour while we debug to improve our MTTR.
As your team gains comfort with the ability to laser target logging, you'll eventually find that this promotes an even stronger practice around operational thinking. Now when you’re reading a PR, you can consider “if this goes sideways, what kind of information would I like to have at my fingertips” and use that to prepare operationally.
Conclusion
How we think about logging has been fundamentally constrained because it's always been hard to change the levels. But it's time to break past this and re-explore the potential of logging.
It's easy to try. You don't need to change your log aggregator. You don't need to change any of your logging code. It's not expensive. These log libraries are implemented as simple filters on top of what your already have. Prefab never see the contents of the logs themselves, it just changes the log level.
If you're looking to improve your MTTR, I'd encourage you to give Prefab a try. It works perfectly with your existing logging solution and is very easy to test on a local branch to get a feel for how it works. If you'd like to see a video it's just 2 minutes. Better yet, signup for Prefab and give it a try. You'll be changing levels in realtime in minutes.
Discussion on Hacker News